Let me walk you through a scenario, really quickly. You have logged into your Google Search Console dashboard, checked the Page Indexing Report, and seen that some crucial URLs have been blocked from indexing, and are appearing under an error message called Blocked by Robots.txt.
Annoying, right?
In this article, we will explore what this error means, where to find the URLs that are impacted by this error and, crucially, how to fix it.
What Does This Error Mean?
The URL Blocked by Robots.txt error means that Googlebot was prevented from crawling a particular URL on your website because of instructions that were located within your robots.txt file.
This could be intentional, or it could be down to an error in your robots.txt file. You may find that, over the course of developing your website, you have added a disallow directive to a URL or a set of URLs that it did not need, and this would be stopping from Googlebot from crawling these URLs.
A disallow directive within your robots.txt file will look something like this:
User-agent: Googlebot
Disallow: /private/
This tells Googlebot not to crawl any of your website’s URLs that start with /private/. If you have a URL, for example, https://example.com/private/page, Google Search Console will show the URL Blocked by Robots.txt error if Googlebot has tried to access it.
A quick note…
Blocking URLs from being crawled may not result in them being excluded from Google’s index. If other websites, or other pages on your website, link to a blocked URL then it could still appear in Google’s index. Just without its content being shown! If you want to prevent a URL from being indexed entirely, you should use the ‘noindex’ meta tag or HTTP header in addition to blocking it in your robots.txt file.
How Do I Find my Blocked by Robots.txt Errors?
You can easily use Google Search Console to find pages that are being impacted by the Blocked by Robots.txt error. First, head to your Google Search Console dashboard:
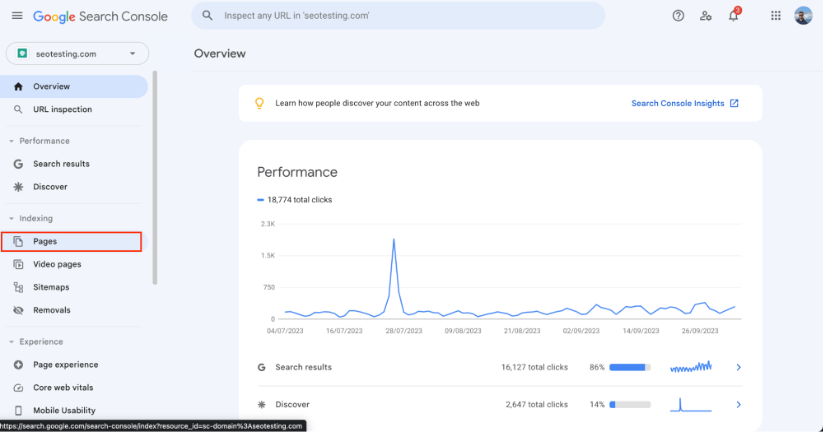
Once you are here, on the left-hand side of the page, click on the “Pages” button that is located within the “Indexing” section of the sidebar:
Once here, scroll down and you will see a list of all your page indexing errors. Here is where you will find any instances of the Blocked by Robots.txt error:
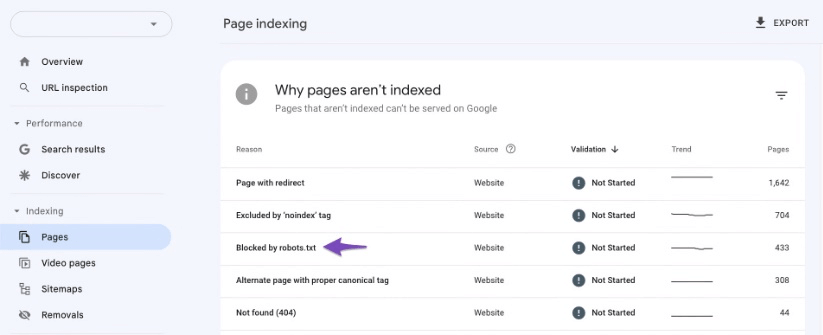
Image Credit: https://rankmath.com/
How Do I Fix my Blocked by Robots.txt Errors?
Before we get into fixing any Blocked by Robots.txt errors on your website, it is worth noting that, sometimes, the error does not need to be fixed. If you are looking at your Google Search Console Page Indexing Report and you realise all of the URLs within the report are URLs that you do not want to be indexed, then you can go ahead and leave this. Google will simply continue to not index these URLs.
If, however, you have noticed that certain URLs that should be indexed are appearing on the report, then it’s time to work.
Head to Google’s Robots.txt Testing Tool
You should first head to Google Search Console’s Robots.txt tester. You may find that your website property is already linked, but if not it is very easy to add. Once you have linked the correct website property to the testing tool, it will load your website’s robots.txt file.
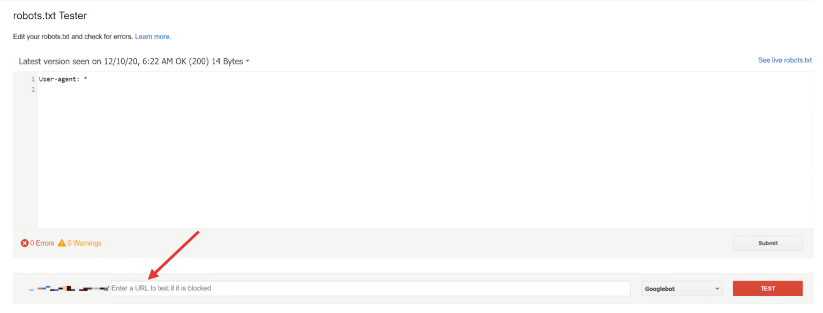
Image Credit: https://aioseo.com/
Once your robots.txt file has been loaded into the website, you should enter a URL at the bottom of the tool that you want to test. Preferably, this should be one of the URLs that is appearing on your Blocked by Robots.txt error list and a URL you want to be indexed.
Select the user agent that you want the tool to test the URL with. We’d recommend leaving Googlebot as the user agent.
Once all the above has been done, click “Test”. The tool will then check this URL against your website’s robots.txt file, letting you know whether the URL has been ACCEPTED or BLOCKED.
Amend your Robots.txt File
If the URL has been blocked, the tool will also highlight the area of the robots.txt file that has blocked the URL. So you know what section of the file to edit or delete. You can do this directly within your robots.txt file on your website, but we’d recommend doing this within the tool itself. This way, you can keep clicking “Test” and checking whether the URL is being blocked or accepted.
Replace your Robots.txt File
Once you have your robots.txt correctly figured, and you have tested your URLs against the new file, you need to replace the robots.txt on your website with this new, amended file, and then re-submit all of the pages you wish to be indexed through Google Search Console.

Blocked by Robots.txt vs Indexed, though Blocked by Robots.txt – What’s the Difference?
This can be a little confusing, so we thought we would add a section to this blog post to talk about the key differences between these two errors for you.
The Blocked by Robots.txt error means that a URL, or multiple URLs, has been clocked from crawling by your website’s robots.txt file. This means that Googlebot has not been able to access the content to include it in its index.
This is, generally, a proactive measure taken by marketers or webmasters to prevent certain pages or sections of their website being indexed accidentally. However, sometimes things do go wrong and the wrong URLs can be included. Hence the reasoning for us writing this article for you.
On the other hand, the Indexed, though blocked by robots.txt error means that, whilst the URL has been blocked from crawling by the website’s robots.txt file, the URL is still being indexed for some reason. This can happen if the URL was previously not in the robots.txt and accessible, or if there are external links pointing to the URL.
Frequently Asked Questions
What does the Blocked by Robots.txt error mean?
It means Googlebot could not crawl a URL because your robots.txt file told it not to. The content is blocked from crawling.
Does Blocked by Robots.txt stop a page from indexing?
Not always. A blocked URL can still appear in search if other pages or external sites link to it. Use a noindex tag to stop indexing fully.
How do I fix a Blocked by Robots.txt error in GSC?
Use the Robots.txt Tester in Google Search Console. Find the rule blocking the URL. Edit or remove the disallow directive. Upload the fixed file.
Should I always fix Blocked by Robots.txt errors?
No. If the blocked URLs are ones you do not want indexed then you can leave them as they are.
What is the difference between Blocked by Robots.txt and Indexed, though blocked by Robots.txt?
Blocked by Robots.txt means Google could not crawl the page. Indexed, though blocked means the page is still in the index from past crawls or links even though it is now blocked.
Can I test if a page is still blocked after changes?
Yes. Use the Robots.txt Tester to check the URL. It will tell you if the page is now accepted or still blocked.
How can I avoid Blocked by Robots.txt mistakes?
Review your robots.txt file after site updates. Keep disallow rules clear and limited to pages you really want to block.
This article should have hopefully given you all the information you need to know about URLs appearing under the Blocked by Robots.txt error. What the error means, and how to fix it.
Looking for a way to get more from your Google Search Console data? Give SEOTesting a try! We have built-out a huge range of custom reports, using your GSC data, to give you more information on new pages being indexed, keyword cannibalization, and more! We have a 14-day free trial with no CC required, so sign up today.
Testimonials
-

"Can totally recommend! It’s not only full of reports to easily identify low hanging fruit opportunities but also, the most straightforward platform to help run SEO tests"
Aleyda Solis, Intl SEO Consultant, Speaker & Author.
-

"SEOTesting.com has become one of my go-to SEO tools because it does so much with all the valuable data hidden in Google Search Console. It's the only thing that gives us the ability to use that data for keyword tracking, SEO tests, and quality testing."
Ruben Gamez, DocSketch