Article Summary (TL;DR)
Blocked Due to Access Forbidden (403) means Googlebot attempted to crawl a URL but was denied access by your server. This usually happens because of server rules, security settings, authentication requirements, or misconfigured files like robots.txt or .htaccess. If the page should be public, the block must be removed so Google can crawl and index it. If the page is intentionally private, the 403 error is expected and does not need fixing.
The Blocked Due to Access Forbidden 403 error within Google Search Console is common. This error occurs when Googlebot attempts to crawl a URL on your website but receives a 403 Forbidden HTTP status code. This response tells Googlebot that it does not have permission to access the content.
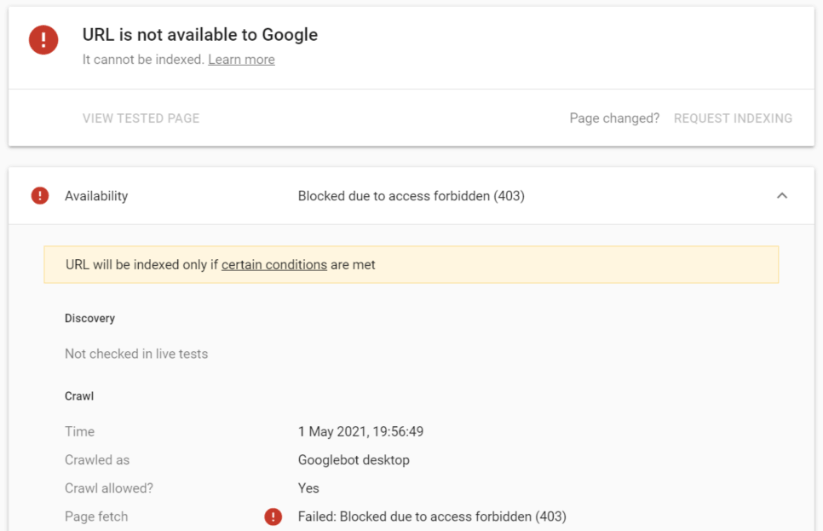
This typically happens because of site rules or server-level access restrictions.
What Causes the Blocked Due to Access Forbidden (403) Error in Google Search Console?
Robots.txt Rules Blocking Googlebot
One of the most common causes of a Blocked Due to Access Forbidden (403) error is your site’s robots.txt file. If Googlebot is explicitly disallowed from accessing a URL, it will be unable to crawl the page and may report this error.
Server-Level IP or User-Agent Restrictions
Your web server may be configured to block certain IP addresses or user agents for security reasons. If these rules include IP ranges or user agents used by Googlebot, Google will be denied access and return a 403 error.
Pages Requiring Login or Authentication
Some areas of a website require login credentials. Googlebot cannot authenticate or log in, so any URLs behind login walls will return a 403 Forbidden response when crawled.
CMS or Plugin Settings Blocking Crawlers
Some content management systems and plugins include crawler-blocking features. If these settings block search engine bots, Googlebot may be prevented from accessing affected URLs, triggering this error in GSC.
Misconfigured .htaccess Rules
On Apache servers, incorrect or overly restrictive rules in the .htaccess file can block Googlebot. Reviewing and correcting these rules is necessary if they are preventing legitimate crawls.
Bandwidth or Rate Limiting Restrictions
Hosting providers sometimes limit request volume. If Googlebot exceeds those limits—such as during heavy crawling or traffic spikes—the server may temporarily block requests and return a 403 response.
Geographic Access Restrictions
Some servers restrict access based on geographic location. If Googlebot is crawling from a blocked region, it may be denied access and receive a 403 error.
Manually Blocking Googlebot by Mistake
Manual changes made by developers or SEO professionals can accidentally block Googlebot. If Googlebot encounters a 403 response due to these changes, the affected pages will appear under this error in Google Search Console. Fixing this requires deciding whether the pages should be accessible to search engines.
How to Find Blocked Due to Access Forbidden (403) Errors in Google Search Console
Head to your Google Search Console dashboard and click on the “Pages” report under the “Indexing” section in the left-hand navigation.
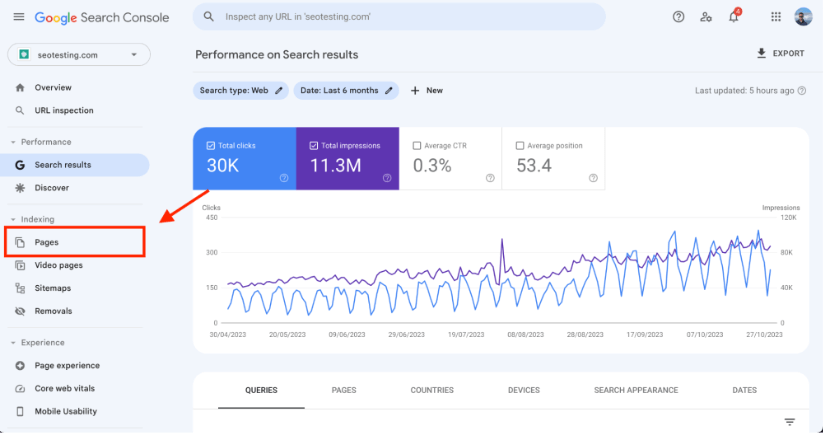
You will see the Page Indexing Report.
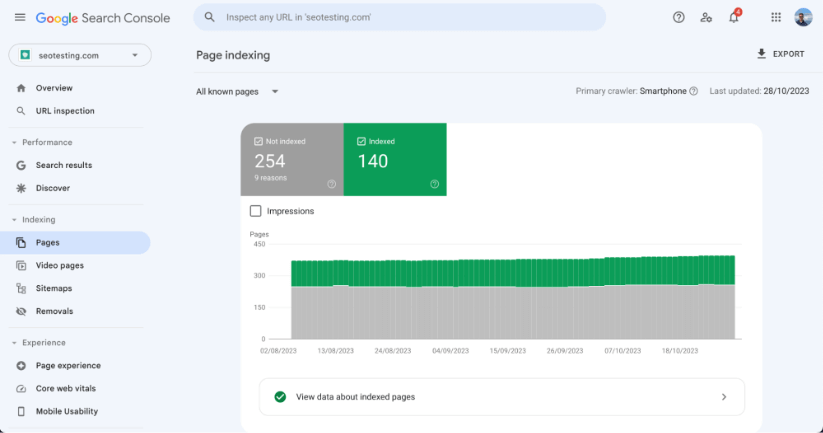
Scroll down to the list of indexing issues. This list shows all indexing statuses detected for your site. Note: This list varies by website.
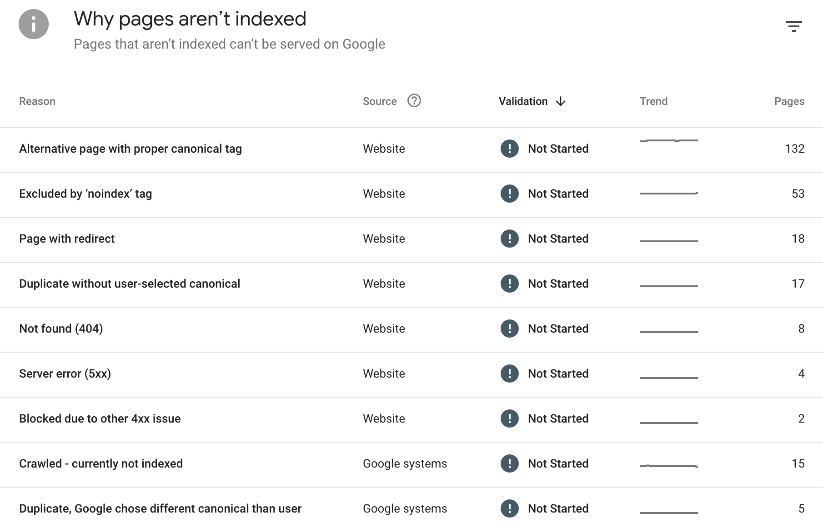
Look for the “Blocked Due to Access Forbidden (403)” status.
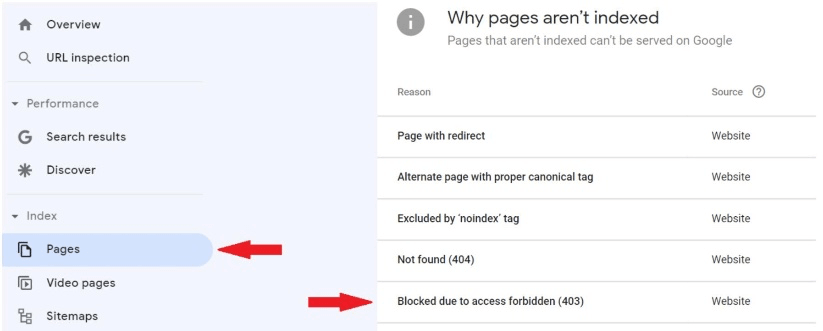
Click into the issue to view all affected URLs and decide whether action is required.
How to Fix the Blocked Due to Access Forbidden (403) Error
To fix a Blocked Due to Access Forbidden (403) error, you must identify what is preventing Googlebot from accessing your pages. Review your website’s:
- .htaccess file
- Server configuration files
- Security plugins
- Firewalls
Remove or adjust any rules that block Googlebot. Confirm the URLs are not disallowed in robots.txt. If the issue is caused by a plugin or firewall, whitelist Googlebot. After making changes, test affected URLs using the URL Inspection Tool and monitor GSC over the next few days to confirm the issue is resolved.
Should You Fix All Pages with an Access Forbidden (403) Error?
You should only fix 403 errors on pages that are meant to be publicly accessible. Public pages must allow Googlebot to crawl and index them in order to appear in search results. If a page is intentionally private or restricted, a 403 response is appropriate and does not need fixing. In those cases, the URLs should also be disallowed in robots.txt to prevent unnecessary crawl attempts.
Frequently Asked Questions
What does Blocked Due to Access Forbidden (403) mean in Google Search Console?
It means Googlebot attempted to crawl a page but the server returned a 403 Forbidden status, indicating access is not allowed.
Is a 403 error the same as a 404 error?
No. A 403 error means the page exists but access is denied. A 404 error means the page does not exist at all.
Can a 403 error prevent a page from being indexed?
Yes. If Googlebot cannot access a page, it cannot index its content or show it in search results.
Why do I see a 403 error in Google Search Console but not in my browser?
Servers can allow access to normal users while blocking bots like Googlebot. This often happens due to firewall rules or user-agent filtering.
What causes 403 errors on WordPress sites?
Common causes include security plugins, firewall rules, misconfigured .htaccess files, restricted admin areas, or hosting-level protections.
How long does it take for Google to remove a 403 error after fixing it?
Once fixed, Google typically re-crawls the page within days. You can speed this up by using the URL Inspection Tool to request reindexing.
Should private pages return a 403 error?
Yes. If a page is intentionally private or restricted, returning a 403 error is correct and helps prevent unwanted access.
Summing Up
The Blocked Due to Access Forbidden (403) error in Google Search Console is common and can directly impact SEO when it affects public pages. It prevents Googlebot from crawling and indexing important content. Resolving the issue requires identifying exactly what is blocking access and correcting it without weakening site security. For private or restricted content, the error is expected and should remain in place. Want to make better use of your Google Search Console data? SEOTesting stores historical GSC data beyond the default 16 months and provides reports to uncover keyword cannibalization, quick wins, and SEO opportunities. Start a 14-day free trial today. No credit card required.
Testimonials
-

"Can totally recommend! It’s not only full of reports to easily identify low hanging fruit opportunities but also, the most straightforward platform to help run SEO tests"
Aleyda Solis, Intl SEO Consultant, Speaker & Author.
-

"SEOTesting has become one of my go-to SEO tools because it does so much with all the valuable data hidden in Google Search Console. It's the only thing that gives us the ability to use that data for keyword tracking, SEO tests, and quality testing."
Ruben Gamez, DocSketch