In SEO, canonical tags (“rel=canonical”) let Google know which URL is to be considered as the main content version, thus helping search engines reduce duplicate results in the SERP.
It is important to note that Google sees all canonical tags as “strong hints” and not directives. So whilst there’s a good chance of Google respecting them, you should not guarantee this to a client, colleague, or manager.
Canonicals are essential for crawlers because they see each of the following URL variations as a different page:
- Protocols (for example, HTTPS and HTTP version).
- Subdomain (for example, WWW and non-WWW version).
- Device type (for example, mobile homepage on m.mydomain.com).
- Session ids (for example, www.domain.com?sid=358).
- Parameters in URLs (for example, www.domain.com?click=E4r3n).
- Upper and lower case variations (for example, www.MYDOMAIN.com).
To add an example to this, it’s important to note that people search in different ways. If two people were coming directly to our website, one might search “www.seotesting.com” while another user may simply type “seotesting.com”. Google, whilst it appears that these are the same URLs, will treat these as completely different pages. Hence why it is important to tell Google which URL should be considered as the main URL.
Want to check a canonical tag is implemented correctly on a page – check out our free Canonical Tag Checker tool which will make sure your tag validates and canonicalizes to the correct URL.
What is Canonicalization?
Canonicalization is the process of using a canonical tag to specify the URL where the main content version is. Google, Yahoo, and Microsoft Bing added support to canonicals back in 2009.
Canonicalization helps consolidate link equity, avoids indexing duplicate results, and makes crawling your site more efficient.
Canonicalization terms explained
When you hear an SEO professional talk about canonicalization, it’s common they will use some industry jargon whilst doing so. I understand this can become confusing to people, especially if you are new to SEO or you have only just started working in the field.
To help, here’s a little jargon buster.
- Canonical tag or rel=”canonical”: the HTML code to specify the main content version URL. This is added to the <head> section of a webpage.
- Canonicalized page or canonicalized URL: A page using a canonical tag to define another page as the canonical URL.
- Canonical page or canonical URL: the URL mentioned in the canonicalized page.
- Self-referencing canonical: a page using a canonical tag mentioning itself.
- rel=”alternate”: the tag for an alternative version of the page. For example, a page for mobile devices (m.domain.com) or a different language.
Reasons to Keep Similar or Duplicate Pages
I know, Google has mentioned many times that they do not like duplicate content on websites. However, there are valid reasons for having more than one page version:
- Page versions for different devices. Like having a separate URL for the desktop and mobile users.
- Dynamic URLs for search and session IDs.
- Having the same pages accessible through different categories on the site. This is particularly useful to those of you who own, run or maintain eCommerce websites.
- Same content on different URL versions. For example, having the same content on the www and non-www URL.
- To syndicate content on different websites.
Note: Google doesn’t demote websites because of duplicate content.
Reasons to use Canonicals
Whilst it is true that Google, along with other search engines, encourages the use of canonical tags because it saves them using valuable resources when crawling, indexing and ranking websites, canonicalization will also help your SEO efforts:
- Consolidates links for duplicate or similar pages into your preferred URL version.
- Specifies the preferred version of the URL you want to be indexed.
- Avoids spending crawl budget on duplicate pages.
- Better manages syndicated content on different websites.
How to Specify Canonical Pages
Now let’s explore the accepted canonicalization methods, their benefits, and limitations.
Using a Canonical Tag (rel=”canonical”)
I would say with confidence that using a canonical tag is both the easiest and the most common way of specifying canonicalized pages.
It’s incredibly easy to implement and you can use it as many times as you like within the same page.
The disadvantages of using canonical tags are:
- It can be complex to maintain on large websites when URLs frequently change, like on eCommerce stores.
- Canonical tags will only work on HTML pages.
- They can have an impact on page size. Whilst this won’t be an issue for many websites, it can become an issue for large eCommerce websites or enterprise sites with lots of URLs.
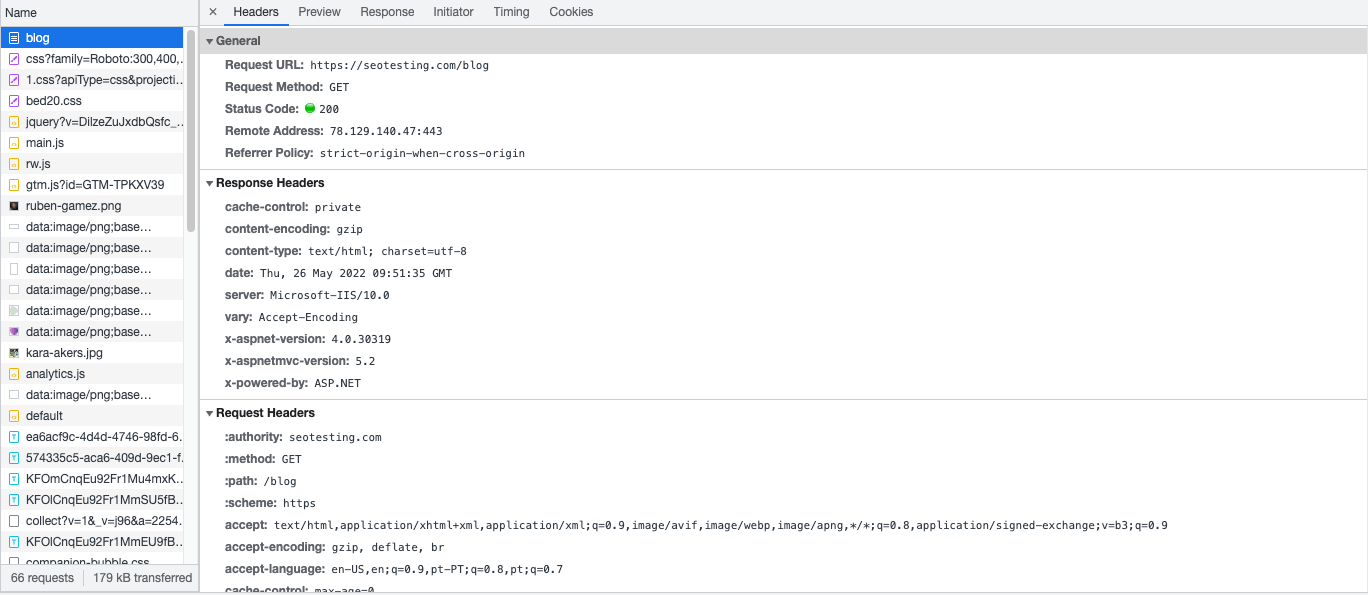
Using HTTP header
HTTP header is the recommended canonical method for all non-HTML pages, like PDFs. A HTTP header has the advantage of not increasing the page size. However, a possible downside is that it can be hard to maintain for larger websites.
Even if it’s a less common practice, you can put a canonical URL in the HTTP header for regular pages.
Best Practises within Canonicalization
We’ve spent some time going over the different methods to canonicalize pages on your website, now I’m going to give you even more value by listing some of the best practises when canonicalizing pages on your website.
Use 1 Canonical Per Page
We mentioned earlier that canonical tags are “suggestions” rather than “directives” and will be treated as such by Google. If you want the best chance of Google following your canonical tag, you should not point one particular page to multiple canonicalized pages.
After all, the purpose of a canonical is to say which version is the main one. Google will ignore canonical tags if you use multiple canonical declarations per page, which removes the benefit of using canonicals.
Be Consistent
Be consistent by always using the same URL format for canonicals. For example, decide if your canonical URLs will have a trailing slash or not.
Google sees URLs as case-sensitive, and you should be clear, so crawlers don’t have to guess what you’re trying to do.
Use Absolute URLs
Google accepts both absolute URLs (www.domain.com/awesome-blog) and relative paths (/awesome-blog) as canonicals. But as John Mueller said on Twitter it is better to use an absolute variation, as they remove the guesswork and lead to better results.
John once gave away some brilliant underrated advice on Reddit: “any time you rely on interpretation by a computer script, you reduce the weight of your input 🙂 (and SEO is to a large part all about telling computer scripts your preferences).”
Don’t Use Noindex Tags and Canonical Tags on the Same Page
Don’t use a noindex and canonical tag on the same page. John Mueller has advised against it several times ( 2009, 2014, and 2018).
In a 2018 Reddit post, John said that Google “generally pick the rel=canonical and use that over the noindex”, but you’ll be relying on interpretation from the crawler.
It’s best to never combine noindex with a canonical attribute as they are contradictory information. In John’s words: “No. you should not combine the noindex with a rel-canonical pointing at an indexable URL (the rel=canonical says they’re equivalent, the noindex says there pretty much opposites). I’d pick one, but not both.”
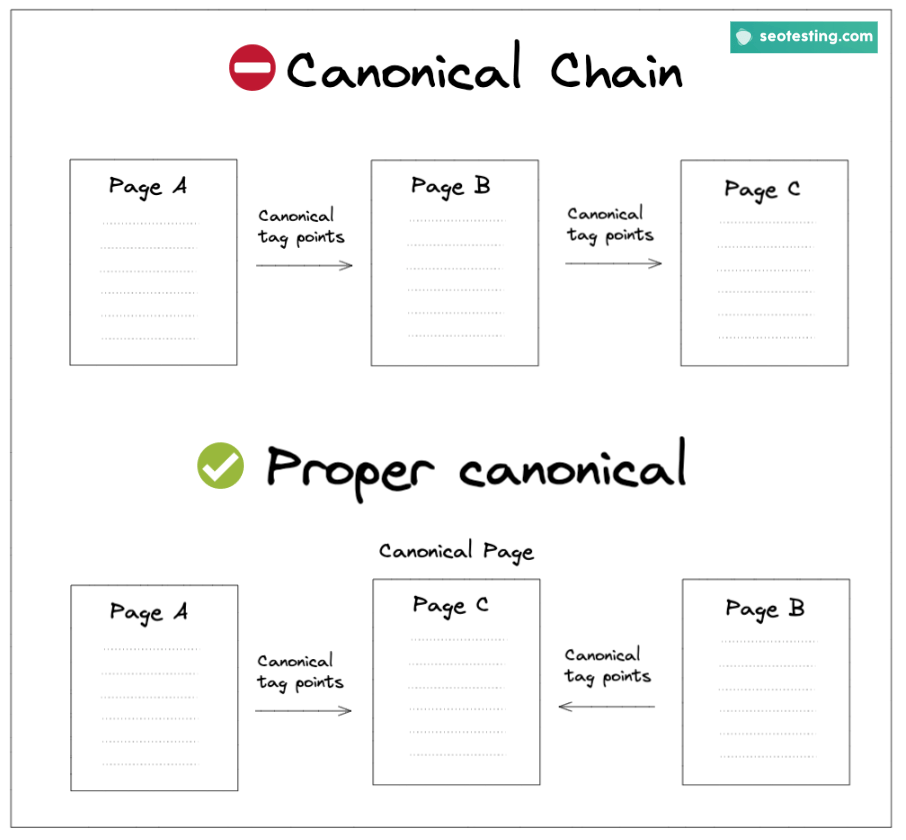
Avoid Canonical Chains Like The Plague
This is, quite possibly, the golden rule when it comes to canonicalization. Please do not declare one page as a canonical URL, and then further canonicalize that page in favour of another. This will confuse Google and every other search engine and give differing versions of which is the best content.
Canonical chains tell search engines that you believe 2 or more pages are the best versions of the content. Fix this by pointing all canonicalized pages to only 1 URL, as you can see in the image below.
Use Double Quotes When Implementing Canonical Tags
The canonical tag (rel=”canonical”) should always use double quotes according to RFC2616. This rule applies to canonicals on link attributes and HTTP headers.
Prioritize HTTPS over HTTP for Canonicals
As a general rule, Google prefers pages using HTTPS over HTTP. But if there are any conflicts with the HTTPS version of your site, they might index the HTTP version.
The main situations that make Google prioritize HTTP over HTTPS are:
- Invalid SSL certificate.
- Page with insecure dependencies (other than images).
- Page with redirects to or through an HTTP URL.
- Page has a canonical to an HTTP page.
According to Google documentation, these are the steps you can take to prevent Google from preferring an HTTP page:
- Redirect all HTTP pages from your site to the HTTPS version.
- Add canonical tags from HTTP to the HTTPS version.
- Fix security certificates warnings/issues.
- Avoid HTTPS to HTTP redirects.
- Avoid including HTTP pages on your sitemap and hreflang tags.
Don’t Place Canonical Tags Within the <body>
Canonical tags should always be in the <head> of the page. Google will ignore any canonical tag in the <body> of the page. It’s also recommended to put the canonical tag in the <head> as early as possible.
Don’t Canonicalize Category Pages to Featured Article / Product Pages
Google doesn’t recommend canonicalizing a category page to a specific article/product, not even when they represent a significant portion of the category page. This is because category pages are supposedly dynamic and represent an umbrella of content and usually aren’t a copy of another page.
A practical example is to think about a category page about running shoes. Setting a canonical to the best selling running shoes will prevent the category page with the list of all the other shoes from appearing in search results.
Sometimes, you don’t (as a user) need the best selling shoe, you may need one completely different so canonicalizing category pages to try and get the best selling shoes to show up (usually in an attempt to increase conversion rates and revenue) will almost never work.
Don’t Canonicalize to First Instances of Paginated Pages
Google recommends not to set the first page from a paginated series as canonical, as these pages aren’t considered a duplication issue on the website.
Pagination shows a list of products or posts archive. So, canonicalization will make accessing different content on the site harder by getting pages removed from the index. Learn more about pagination and best practices in this guide.
How to Find Canonical Pages within Google Search Console (GSC)
The coverage report is the most effective way to find a list of the pages with canonical tags on Google Search Console. Then look for these types:
- Alternate page with proper canonical tag (Excluded tab).
- Duplicate without user-selected canonical (Error tab).
- Duplicate, Google chose a different canonical than user (Excluded tab).
- Duplicate, submitted URL not selected as canonical (Error tab).
Summary
Canonicals help search engines save resources and avoid indexing duplicate content, but when done correctly, they can also lead to improvements of your website’s SEO. Therefore, I recommend paying close attention to Google Search Console to see if they accept your canonicals.
If you want to know all the queries your pages rank for and not just the 1000 that Google Search Console shows, sign up to SEOTesting. We have a 14-day free trial (no credit card upfront).
Testimonials
-

"Can totally recommend! It’s not only full of reports to easily identify low hanging fruit opportunities but also, the most straightforward platform to help run SEO tests"
Aleyda Solis, Intl SEO Consultant, Speaker & Author.
-

"SEOTesting.com has become one of my go-to SEO tools because it does so much with all the valuable data hidden in Google Search Console. It's the only thing that gives us the ability to use that data for keyword tracking, SEO tests, and quality testing."
Ruben Gamez, DocSketch