Logging into your Google Search Console dashboard, entering your page indexing report and finding the error message listed as Duplicate Without User-Selected Canonical can be incredibly frustrating.
In this article, we'll talk in-depth about this error message. We will talk about what the error message actually means, why the message is important and whether you need to fix it and, of course, we will talk about how to fix the error message too.
Let's get into it.
What is the Duplicate Without User-Selected Canonical Error? What Does It Mean?
The Duplicate Without User-Selected Canonical error message indicates that Google has found duplicate content on your website, but it lacks a user-selected canonical tag (essentially a canonical tag that you have placed yourself) to indicate which version of the content should be considered the 'primary' or 'preferred' one for indexing and ranking purposes.
To put it simply, Google's algorithms have found multiple pages on your site with very similar or even identical content, but there is no clear indication from your website's coding (through the canonical tag within the HTML) as to which page you want prioritised within search results. This can lead to a lot of confusion for search engines, as they may not know which version to display in search results, and it can potentially harm your website from an SEO standpoint.
Why is this Error Important?
The Duplicate Without User-Selected Canonical error message is an important one because it shows a potential SEO issue that can harm your website's search rankings, as well as the user experience.
This error indicates that there are multiple similar or identical pages on a website that lack a canonical tag from the user. Without this canonical tag, search engines may struggle to determine which page to rank. This can lead to issues with keyword cannibalisation, diluted SEO efforts and even decreased visibility in the SERPs.
Do I Need to Fix this Error?
Addressing this error is generally recommended for maintaining a healthy and optimised website. It's crucial if you want to improve search engine rankings and provide a better user experience.
Ignoring this error can lead to keyword cannibalisation, lower search visibility, and potential user confusion, especially for larger websites. Implementing canonical tags, especially self-referencing canonical tags, is considered an SEO best practice, ensuring that search engines understand the preferred version of your pages.
While the urgency to fix it may vary, it's advisable to prioritise resolving this error for long-term SEO success.
How to Fix the Duplicate Without User-Selected Canonical Error
Now we understand what the error is, what it means for your website and you've got a clear idea of whether you need to fix it or not, let's take a look at how to fix it on your website.
There are a few ways to do this, so we've taken a look at all of them for you to take the effort out of your decision making.
Identify the URLs with the Error
The first step is to find all the pages with this error. To do this, head to your Google Search Console dashboard.
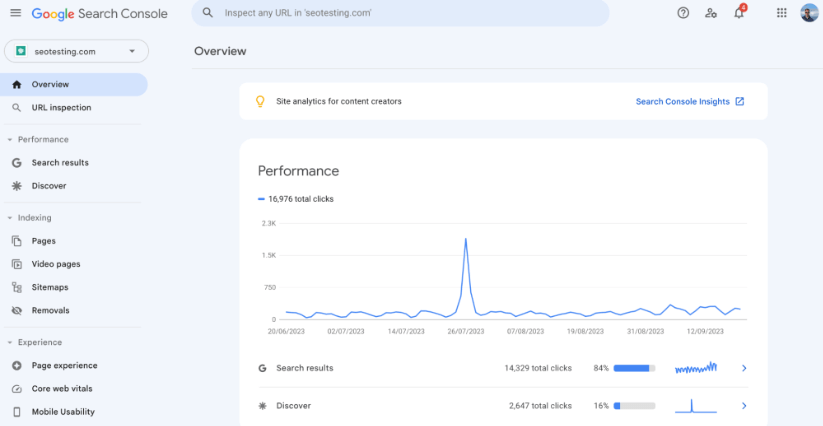
Once here, take a look at the left-hand side of your screen. Under the "Indexing" tab, you can see your page indexing report.
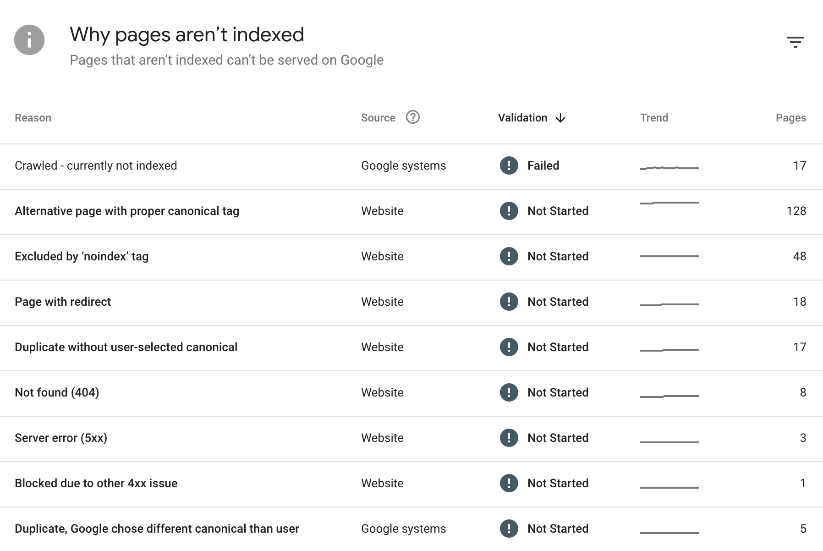
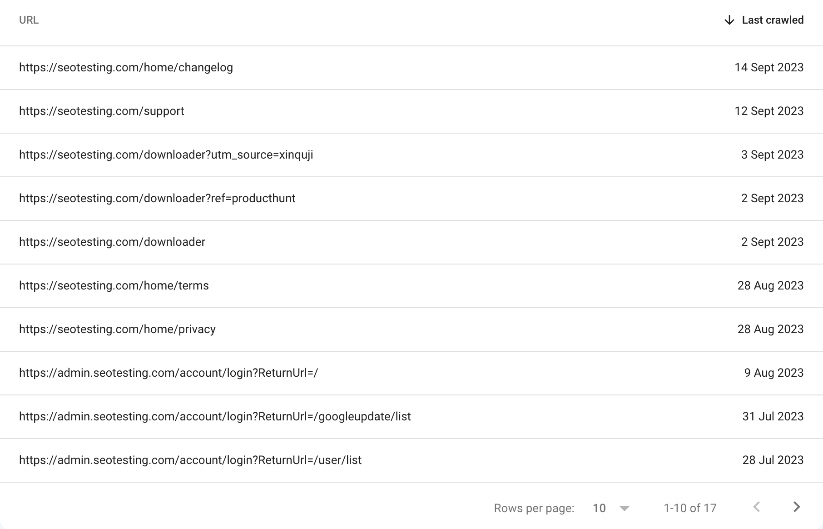
Once situated on your page indexing report, scroll down on the page to find all your pages with page indexing errors. There, you may find (if there are pages with this error) the error message listed as Duplicate Without User-Selected Canonical.
As you can see from our example below, we have 17 pages with this error.
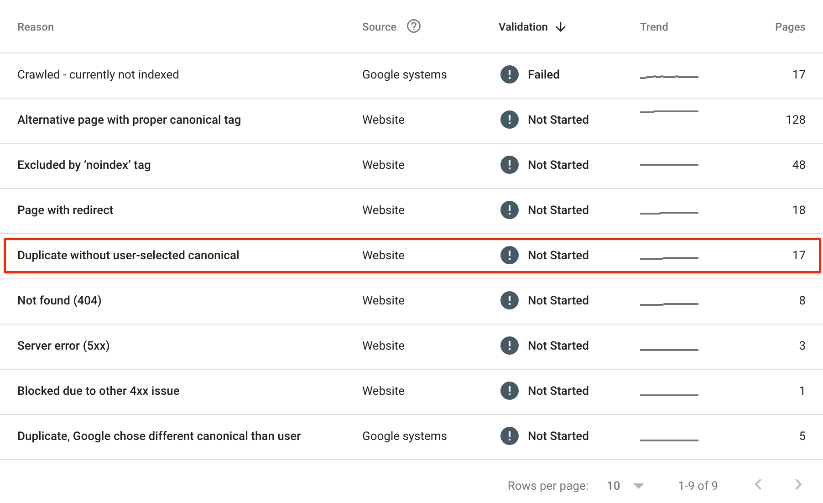
Click into this error message, and you will be greeted with all the URLs on your site with this error message.
Implement a 301 Redirect
Sometimes, you may have similar or duplicate pages on your site where these duplicates do not need to be there. In this instance, the best way to solve the error is to implement 301 redirects on all the pages you do not wish to be indexed, and redirect them to the page that you want to be indexed.
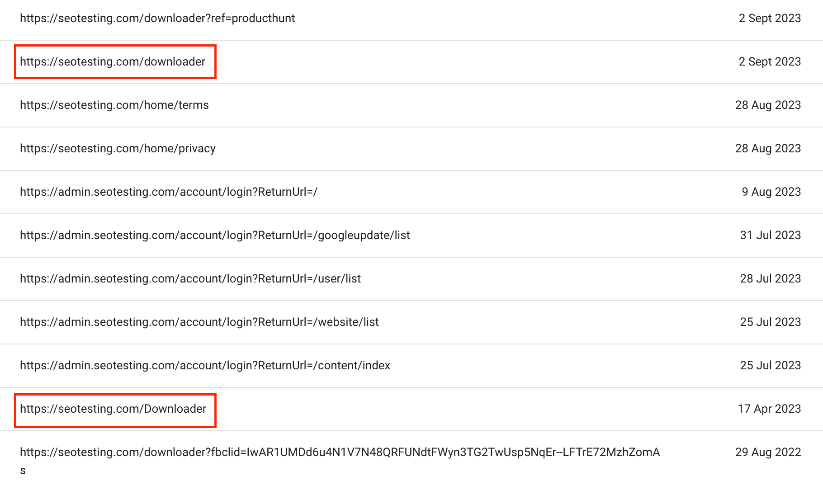
For example, if we have two URLs on our website:
- https://seotesting.com/downloader/
- https://seotesting.com/Downloader/
Google is, effectively, treating these URLs as duplicate content, as it is seeing them as different pages. We can see this in our report, showing these URLs as pages listed with the Duplicate Without User-Selected Canonical error:
The best way for us to solve this problem is to 301 redirect one of these URLs to the other one. This will, eventually, force Google to remove the page with the redirect from the index as we are telling it that it has been permanently moved.
It's also worth noting that neither of these pages is listed with a canonical tag. We will talk more about this in the next section, as this is another valid fix. But in this case, as the URLs contain identical content, a 301 is the best fix.
Implement a Canonical Tag
Using the same example above (the duplicate content with URLs containing different capitalisation), we could implement a canonical tag to both pages to fix the issue.
For example, we could take the https://seotesting.com/downloader/ URL and give this a self-referencing canonical. Meaning we are selecting the canonical tag as that URL. Then, for the capitalised URL ( https://seotesting.com/Downloader/), we could list the canonical as the URL without a capital.
What this shows Google is we are saying treat the non-capitalised URL as the main URL, and remove the other page from your index.
This fix also works for trailing "/" within the URL. For example, if I was an ecommerce store owner and I had two URLs:
- https://mysite.com/category/product
- https://mysite.com/category/product/
Google will be treating these URLs as different pages, even though they are the same page. We can add a self-referencing canonical to one of these URLs and then point the other URL to that self-referencing canonical and the issue would be resolved.
Implement a Noindex Tag
There are also some URLs within our example that, clearly, do not need to be indexed.
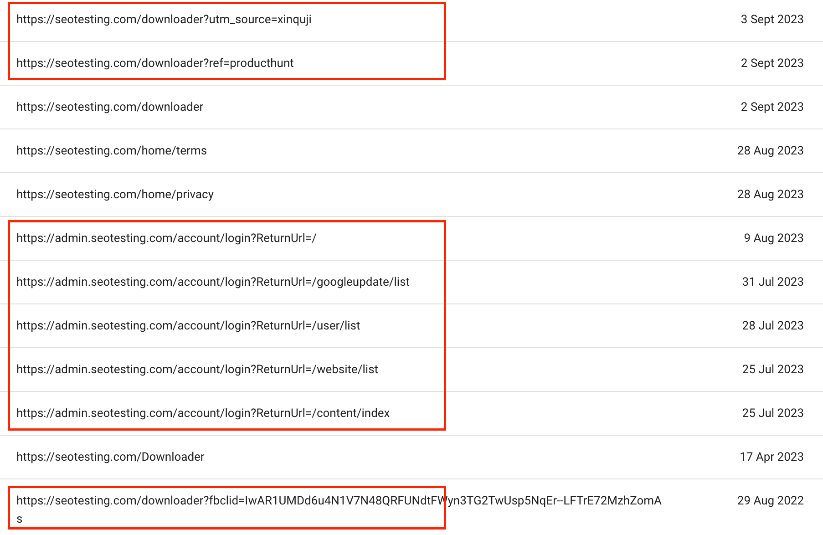
The easiest option to "fix" these pages and stop them from showing up on this particular report is to implement a noindex tag within the source code of each of these URLs. We do not need these URLs in the index, showing up in Google search results, so the easiest option is to ask Google not to index them. The best way to ask Google to not index a page, implement a noindex tag.
De-Duplicate Content
Sometimes, you may have pages listed within this report that genuinely are duplicate content, at least in the eyes of Google's crawlers, anyway.
If this is the case, the first step you should take (before thinking about implementing canonical tags, although this is best practice) is to de-duplicate the content. Change one (or both) pieces of content to ensure they are unique enough for Google to consider both of them for indexing. This is the easiest way to get these types of pages removed from this report section.
For example, you may have two very similar blog posts (following years of content marketing work) which Google considers as duplicate content:
- https://mysite.com/blog/keyword-cannibalisation/
- https://mysite.com/blog/keyword-cannibalisation-guide/
You should work through both pages and ensure there are enough differences within them to allow Google to index both.
Failing that, of course you can head to the above fix and implement canonical tags. This will suggest to Google that you consider both pages as unique and may fix the error anyway. Ideally, however, both pages should have a self-referencing canonical tag and be unique content!
Verify the Fix
Once you have been through and implemented any redirects, canonicals and noindex tags, you need to verify the fix with Google Search Console. Validating the fix will ask Google to re-crawl all the impacted pages to see whether the error is still valid, or if they can be removed from the report.
You will see on your report, at the top of the page, a section that allows you to validate the fixes you have put into place:
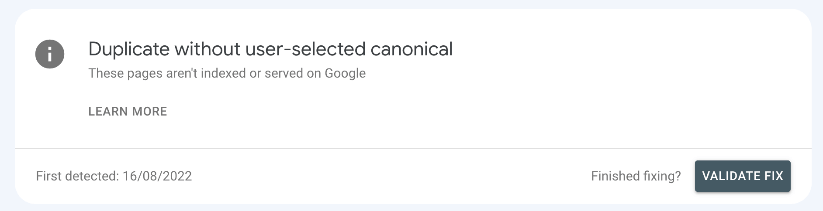
Click "Validate Fix" and this will ask Google to re-crawl impacted pages. If Google can no longer find a duplicate page without a user-selected canonical, they will remove this page from the report.
Want to make more of your Google Search Console data, store it for longer than 16 months, and use it to both inform and run SEO tests? SEOTesting is the ideal solution for you. We're currently running a 14-day free trial, with no credit card required to sign-up. Give us a try, and start testing today.
Testimonials
-

"Can totally recommend! It’s not only full of reports to easily identify low hanging fruit opportunities but also, the most straightforward platform to help run SEO tests"
Aleyda Solis, Intl SEO Consultant, Speaker & Author.
-

"SEOTesting.com has become one of my go-to SEO tools because it does so much with all the valuable data hidden in Google Search Console. It's the only thing that gives us the ability to use that data for keyword tracking, SEO tests, and quality testing."
Ruben Gamez, DocSketch