The ecommerce industry in the US is on track to reach over $ 2.1 trillion by 2029. That’s nearly double what it was in 2023.
Ecommerce is growing fast. However, with increased traffic and sales comes increased competition. To stand out, you need more than just great products. Your site must also be fast, structured, and easy to crawl.
That’s where technical SEO makes a big difference!
This article will break down the key technical areas that all ecommerce sites should be focusing on in order to improve rankings and drive sales growth.
Key Takeaways
- Technical SEO drives sales growth – A well-optimized site helps search engines discover and index your products, leading to more organic traffic and revenue.
- Start with the fundamentals – Focus on robots.txt optimization, XML sitemaps, and Google Search Console setup before tackling advanced techniques.
- Mobile-first is ALWAYS a non-negotiable – With mobile driving most ecommerce traffic, responsive design and fast mobile page speeds directly impact your bottom line.
- Core Web Vitals can affect rankings – Page speed metrics like Largest Contentful Paint and Interaction to Next Paint can influence both user experience and search visibility.
- Structured data gives you competitive advantages – Product schema and review markup make your listings stand out in search results with rich snippets.
- Platform-specific optimization can deliver quick wins – Shopify, WooCommerce, Magento, and BigCommerce each offer built-in SEO features you can enable immediately.
- Monitoring prevents disasters – Regular Google Search Console checks catch crawling errors and indexing issues before they hurt your rankings.
- Focus on high-impact pages before anything else – Prioritize technical improvements on your homepage, main category pages, and best-selling product pages for maximum ROI.

Table of Contents
- Ecommerce Technical SEO Fundamentals
- Site Architecture and URL Structure
- Page Speed and Core Web Vitals
- Mobile Optimization and User Experience
- Structured Data and Schema Implementation
- Crawlability and Technical Optimization
- Platform-Specific Quick Wins
- Monitoring and Measurement
Ecommerce Technical SEO Fundamentals
Technical SEO helps search engines discover, crawl, and index your ecommerce website. Each step links to the next. Together, they form a chain. That chain decides if customers can find your products in search results.
Discovery starts when search engines send crawlers (bots) to your site.
These bots first check your robots.txt file. This file sets the rules. It tells crawlers which pages they’re allowed to visit and which pages they’re not allowed to access.
Place the robots.txt file in your root directory. Link to your XML sitemap inside it.
Your XML sitemap comes next.
Your XML sitemap helps crawlers find your most important pages, like:
- Product pages
- Category pages
- Key landing pages
Submit the sitemap to Google Search Console. This can help Google index your content more quickly.
Crawling happens after discovery.
Crawlers follow internal links to move through your site. They fetch and scan the content of each page. The better your site structure, the easier this process becomes.
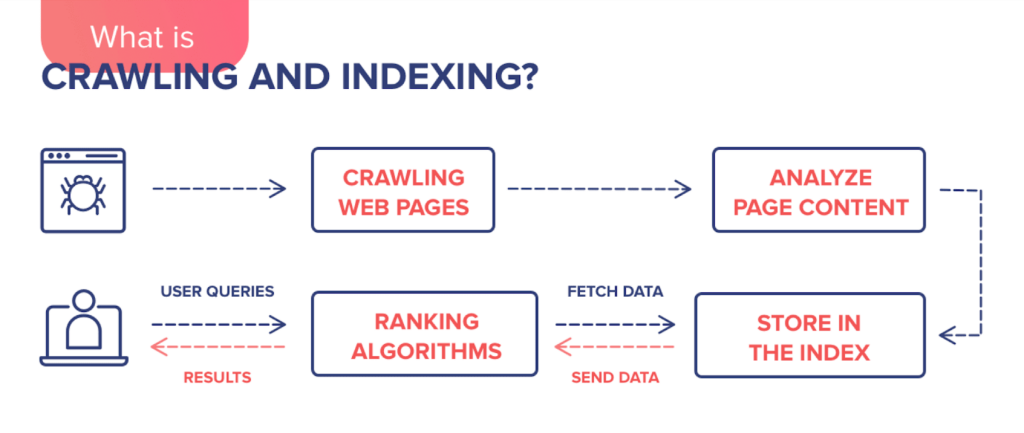
Next comes indexing.
This is when Google decides which pages to store in its database.
For ecommerce sites, this can get messy. Filters and variants create many URLs with the same content. Use canonical tags to inform Google of the primary version of your content. This prevents duplicate content and protects your rankings.
Google Search Console tracks this whole process.
GSC shows how Google sees your site. Check it each week for:
- Crawl errors
- Indexing issues
- Mobile usability problems
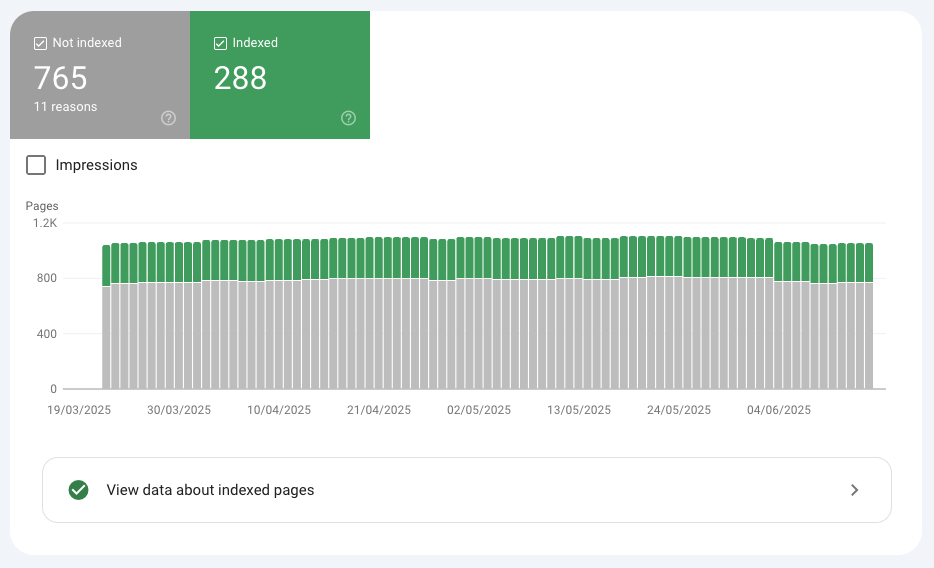
Use this data in your SEO audits. Look for broken links, slow pages, or missing meta descriptions. Fixing these problems keeps your technical SEO chain strong.
Make your site easy to crawl.
Create simple paths from your homepage to every product. Use breadcrumb navigation. Use internal links that make sense. Each link provides crawlers with another way to discover your content.
Track your indexing status to spot issues early.
If products don’t appear in search results, determine where the chain breaks. The problem could be crawl permissions. It could be a sitemap issue. Or a block in indexing.
Ecommerce Technical SEO Fundamentals Checklist
- Add a robots.txt file to your website’s root directory.
- Include a link to your XML sitemap in the robots.txt file.
- Create and submit an XML sitemap in Google Search Console.
- Ensure your sitemap includes key pages (product, category, and landing pages).
- Check your site’s internal linking structure to support efficient crawling.
- Use canonical tags to manage duplicate content from filters and variants.
- Review GSC weekly for crawl errors, indexing issues, and mobile usability problems.
- Use GSC data in SEO audits to find broken links, slow pages, or missing meta descriptions.
- Simplify navigation paths from the homepage to every product.
- Implement breadcrumb navigation to improve site hierarchy.
- Ensure all internal links are relevant and useful for discovery.
- If a product isn’t showing in search, check for crawl blocks, sitemap exclusions, or indexing issues.
Site Architecture and URL Structure
Your ecommerce site’s architecture shapes how customers and search engines navigate your site. A well-planned structure makes products easy to find while preventing technical issues that can harm your rankings.
Building a Logical Site Hierarchy
Build your site architecture like a pyramid with your homepage at the top. Category pages sit below the homepage, organizing your products into logical groups. Product pages form the foundation, each accessible through clear paths from the categories above. This hierarchy helps customers understand your store layout while giving search engines a roadmap to follow.
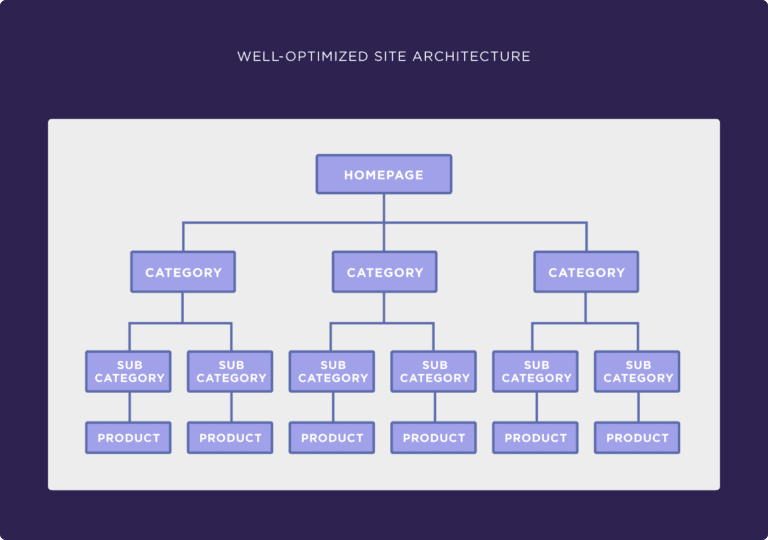
Design your URL structure to match this logical flow. Clean, descriptive slugs are more effective than random numbers or codes. Use:

These readable URLs help customers understand their location and make sharing easier.
Navigation that Guides Users
Create navigation menus that accurately reflect your site’s architecture.
Your main menu should feature your most important categories, while breadcrumbs show the path from the homepage to the current page.
Breadcrumbs, such as “Home > Electronics > Smartphones > iPhone 16,” help users backtrack and provide search engines with context about the relationships between pages.
Internal linking connects your architecture. Link from category pages to relevant products and connect related products. These links distribute authority throughout your site while helping customers discover new items. Every page should be reachable within three clicks from your homepage.
Managing Faceted Navigation and Parameters
Handle faceted navigation carefully to avoid duplicate content issues. When customers filter products by:
- Color
- Size
- Price
You create new URLs with different parameters. Use canonical tags or URL parameter handling to prevent these filtered pages from competing with your main category pages in search results.
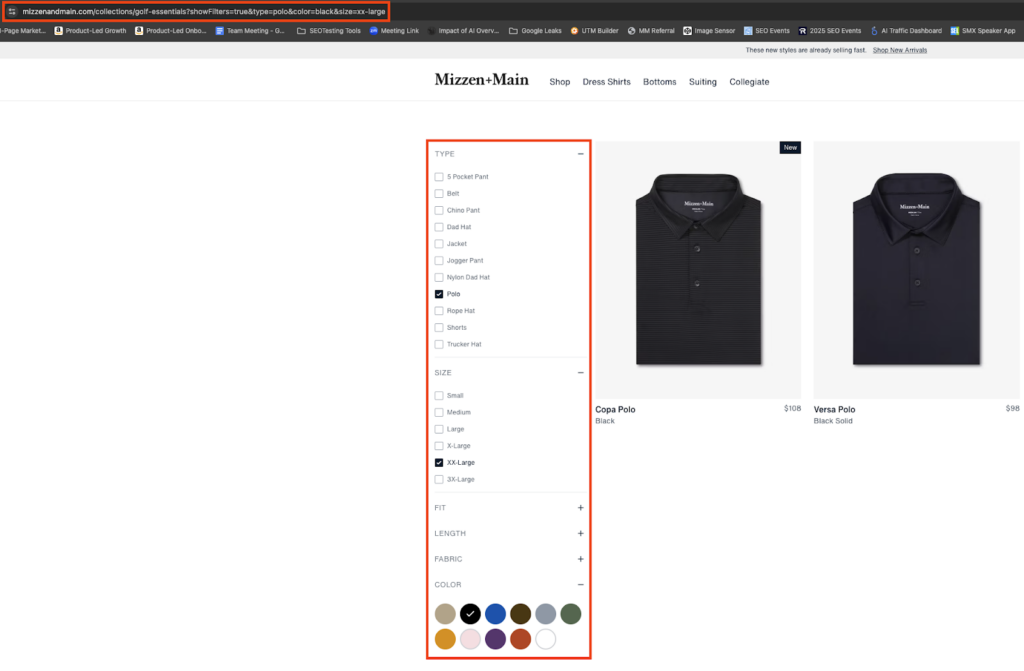
Keep your URL parameters clean and consistent. Parameters like “?color=red&size=large” should follow a logical order and use standard naming conventions. Too many random parameters create messy URLs that confuse both users and search engines.
Monitor how your architecture performs by checking which pages get the most internal links and traffic. Strong category pages should drive visitors to product pages through clear navigation paths. If customers can’t find products easily, your architecture needs simplifying.
Remember that every structural design affects user experience and search performance. Simple, logical organization beats complex category systems that confuse visitors. Focus on making your site easy to browse, and the technical benefits will follow.
Site Architecture and URL Structure Checklist
- Map out a pyramid-style site structure: Homepage → Categories → Subcategories → Products.
- Ensure each product page is accessible via clear, logical paths from category pages.
- Use clean, descriptive URLs that reflect your site’s hierarchy (e.g. /category/product-name).
- Avoid using unreadable URLs with IDs or random codes.
- Add a main navigation menu that features your top categories.
- Implement breadcrumb navigation on all pages to show the user path.
- Link from category pages to individual products, and between related products where relevant.
- Keep all important pages within 3 clicks of the homepage.
- Use canonical tags or parameter handling to control duplicate content from filtered URLs.
- Keep URL parameters clean and consistently ordered (e.g. ?color=black&size=xxl).
- Monitor internal linking patterns to ensure authority flows to key product and category pages.
- Simplify any overly complex category structures that could confuse users or search engines.
Page Speed and Core Web Vitals
Fast-loading pages keep customers engaged and can improve your search rankings.
Google’s Core Web Vitals measure the real user experience on your ecommerce site, making page speed optimization essential for both sales and visibility.
Understanding Core Web Vitals Metrics
Core Web Vitals focus on three key user experience areas:
- Largest Contentful Paint (LCP)
- Interaction to Next Paint (INP)
- Cumulative Layout Shift (CLS)
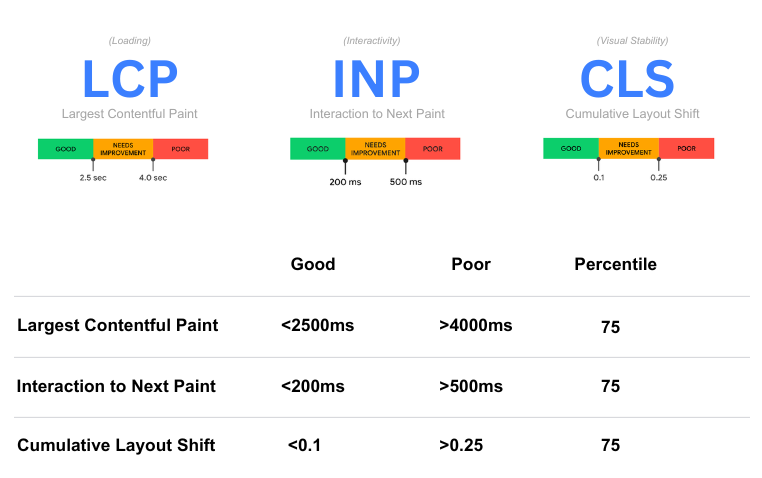
Largest Contentful Paint measures how quickly your content loads. Ideally, it should be under 2.5 seconds. Customers expect to see product images and descriptions quickly, especially on mobile devices.
Interaction to Next Paint tracks how responsive your site feels when customers click buttons or tap links. Quick responses under 200 milliseconds create smooth shopping experiences. Slow interactions frustrate users and can lead to abandoned carts.
Cumulative Layout Shift measures visual stability as your page loads. When elements jump around unexpectedly, customers might accidentally click the wrong buttons. Keep this metric below 0.1 to maintain a stable, trustworthy interface.
Measuring and Monitoring Performance
Google PageSpeed Insights provides real-world data on how customers experience your site’s speed. It combines lab data with actual user metrics to show where performance problems occur. Check your key pages monthly to catch issues before they impact conversions.
Lighthouse provides detailed audits that break down specific optimization opportunities. Run Lighthouse tests on your product pages and category pages to identify which elements slow down loading. The tool suggests practical fixes you can implement immediately.
Optimization Techniques That Work
Image compression can sometimes deliver the biggest speed improvements for ecommerce sites. Large product photos can significantly slow down page loading. Compress images without losing visual quality, and use modern formats like WebP when possible.
Lazy loading delays loading images until the customer scrolls down to view them. This technique speeds up initial page loads while still showing all your product images. Implement lazy loading on category pages that display a large number of product thumbnails.
Content Delivery Networks (CDNs) distribute your files across multiple servers worldwide. When customers visit from different locations, they receive content from the server closest to them. This reduces loading times globally and improves the shopping experience for international customers.
Browser caching stores frequently used files on customers’ devices. Return visitors load pages faster because their browsers don’t need to download the same images and scripts again. Set proper cache headers to strike a balance between fresh content and speed benefits.
Minification removes unnecessary code from your CSS and JavaScript files. Smaller files download faster while maintaining the same functionality. Most modern build tools can minify your code automatically during deployment.
Focus on your most important pages first:
- Homepage
- Main category pages
- Top-selling product pages
These pages create the most traffic and revenue, so speed improvements here deliver the most significant business impact.
- Monitor Core Web Vitals:
- LCP (aim for < 2.5s)
- INP (aim for < 200ms)
- CLS (aim for < 0.1)
- Run Google PageSpeed Insights monthly on key pages to detect performance issues.
- Use Lighthouse audits on product and category pages to find and fix slow-loading elements.
- Compress large product images to reduce load times without sacrificing quality.
- Convert images to modern formats like WebP where possible.
- Implement lazy loading on category and product listing pages with many thumbnails.
- Use a Content Delivery Network (CDN) to serve content faster to users in different locations.
- Enable browser caching to improve load times for repeat visitors.
- Minify CSS and JavaScript files to reduce file size and speed up downloads.
- Prioritize speed improvements on high-traffic pages: homepage, main category pages, and top-selling products.
Mobile Optimization and User Experience
Mobile drives the majority of ecommerce traffic. Google’s mobile-first indexing means that your mobile site version determines where you rank, making mobile optimization hugely important for both user experience and visibility.
Mobile Commerce Considerations and User Behavior
Mobile users behave differently than desktop users. They browse with their thumbs, expect instant loading, and abandon sites that require pinching and zooming. Your mobile experience needs to accommodate these unique behaviors to capture sales.
Mobile page speed becomes even more important on smaller screens. Customers on cellular connections have less patience for slow-loading product images or checkout forms. Optimize your mobile pages to load in under three seconds to prevent cart abandonments.
You may be tempted to explore the use of Accelerated Mobile Pages on your ecommerce site. While this can improve loading speeds, there are too many potential drawbacks for ecommerce websites, and AMP is generally not recommended for use on ecommerce sites at all.
Responsive Design Best Practices
Responsive design automatically adapts your site layout to any screen size. Your viewport settings control how pages are shown on mobile devices, ensuring the content fits properly without any horizontal scrolling. Set your viewport meta tag correctly to prevent scaling issues.
Design your layout to work touch-first. Desktop hover effects don’t translate to mobile screens, so ensure all functionality works with touch gestures. Customers should be able to access all features using:
- Taps
- Swips
- Pinches
Without missing functionality.
Touch-Friendly Navigation and Checkout Optimization
Tap targets need sufficient spacing to prevent accidental clicks. Make buttons at least 44px tall and wide, with enough space between clickable elements. Customers using their thumbs need room to tap accurately, especially during checkout.
Hamburger menus work well for organizing navigation on small screens. Hide secondary menu items behind a recognizable three-line icon to save space while keeping your main categories accessible. Ensure your hamburger menu opens quickly and displays clearly.
Optimize your checkout process specifically for mobile users. Reduce form fields to only essential information, enable autofill for addresses and payment details, and use large, clear buttons for completing purchases. Mobile checkout abandonment rates are higher, so every friction point results in lost sales.
Consider mobile-specific user experience improvements, such as one-thumb navigation, which allows customers to access all important elements using just their thumb. Place search bars, cart icons, and main navigation all within easy reach of the bottom half of the screen.
Mobile usability is more than just making sure content fits on smaller screens. It means ensuring your site loads quickly, features intuitive touch interactions, and has a fast buying process in place. All of this works to create a smooth mobile experience that converts browsers into buyers.
Mobile Optimization and User Experience Checklist
- Ensure your mobile site loads in under 3 seconds to reduce bounce and cart abandonment.
- Avoid using AMP on ecommerce pages, as it introduces limitations not suited for online stores.
- Use responsive design to automatically adjust layout across screen sizes.
- Set the correct viewport meta tag to prevent horizontal scrolling or scaling issues.
- Make sure all functionality works via touch. No hover-only interactions.
- Test gestures like tapping, swiping, and pinching to ensure full usability.
- Make tap targets at least 44px in size, with enough spacing between interactive elements.
- Use a hamburger menu to simplify navigation and keep it easy to access.
- Design a mobile-friendly checkout flow with:
- Fewer form fields
- Autofill enabled
- Large, clear action buttons
- Adopt one-thumb navigation principles:
- Keep key elements (search, cart, nav) within easy reach at the bottom of the screen.
Structured Data and Schema Implementation
Structured data allows search engines to better understand your products and display them in rich results. These enhanced search listings show:
- Star Ratings
- Prices
- Availability
Directly in search results, making your products stand out from competitors.
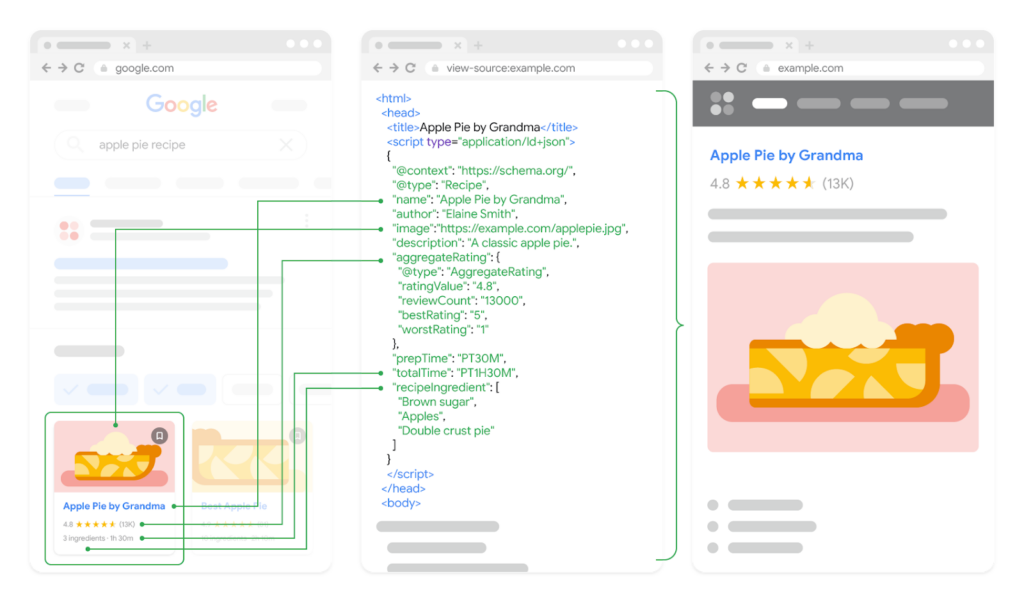
Adding structured data using Schema.org vocabulary connects your ecommerce site to the Knowledge Graph that powers search engines. This structured data helps Google understand what you’re selling and shows relevant details to potential customers.
Essential Ecommerce Structured Data Types
Product schema forms the foundation of ecommerce structured data. Mark up essential details, such as product name, description, price, availability, and brand information. This data enables rich results that show product information directly in search listings, increasing click-through rates.
Using Product schema can also help you obtain product snippets and merchant listings for your products on the Google SERPs! This can improve your click-through rate and bring in more site visitors without requiring an increase in your average position for each search query.
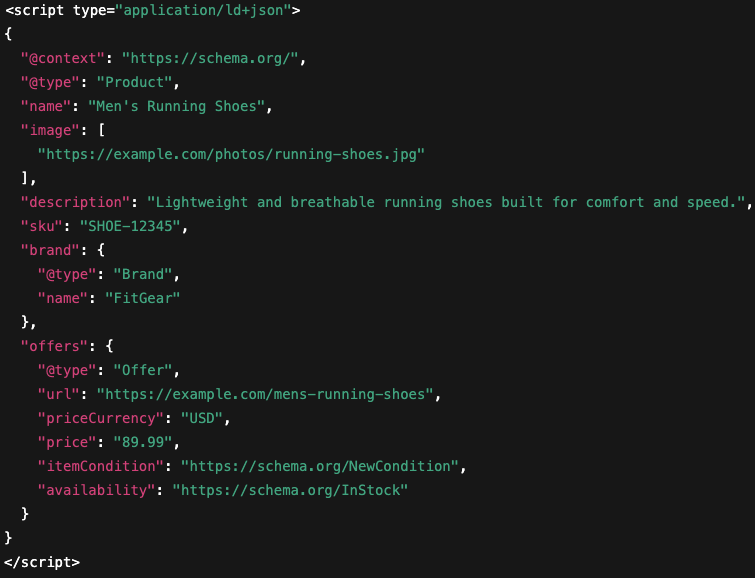
Review schema adds customer ratings and review counts to your search listings. Star ratings displayed in search results build trust and attract more clicks than plain text listings. Include aggregate rating information and individual review details to maximize visibility.
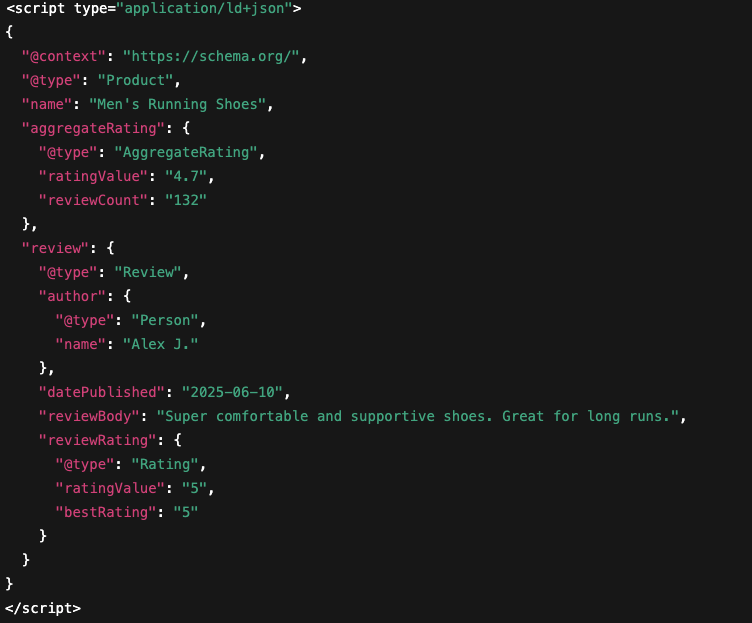
Breadcrumb schema helps search engines understand your site structure and can display navigation paths in search results. This structured data displays the category hierarchy, enabling customers to understand where products fit within your store’s organization.
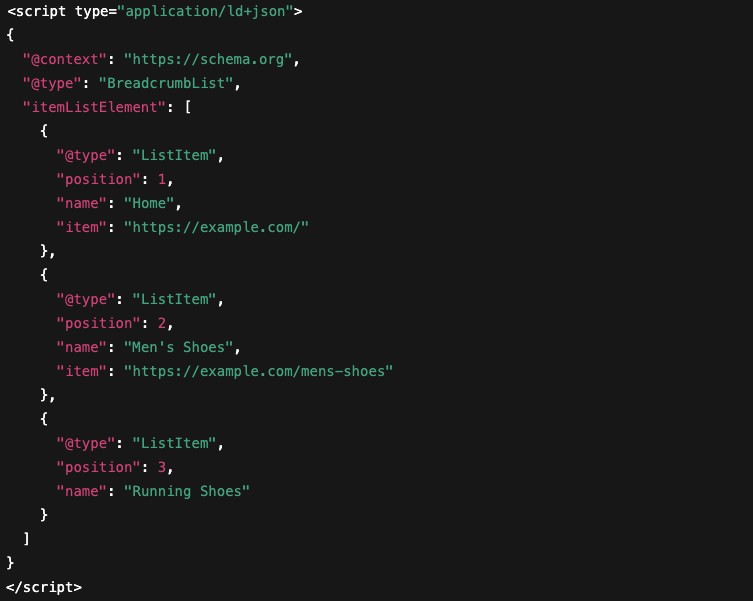
JSON-LD gives you the cleanest way to include structured data without cluttering your HTML. JSON-LD is JavaScript based and separates your structured data from the visible content on your site. This makes it easier to maintain and update without impacting your page design.
Product Schema Implementation
Implement product schema on every product page with complete information. Include required properties like:
- Name
- Description
- Offers
Plus optional details like:
- Brand
- Model
- Product Identifiers
More complete data increases your chances of earning rich results.
Mark up pricing information accurately, including currency, availability status, and any sale prices. Google displays this information prominently in search results, so ensure your structured data matches your visible pricing exactly to avoid policy violations.
Add product images using the image property within your product schema. Multiple high-quality images increase your chances of appearing in image search results and Google Shopping feeds.
Review and Rating Schema
Implement review schema to show customer feedback in search results. Include both individual review details and aggregate rating summaries to provide comprehensive social proof. Star ratings in search listings can significantly improve click-through rates.
Ensure your review data accurately reflects actual customer reviews on your site. Only mark up genuine reviews to maintain compliance with search engine guidelines. Fake or manipulated review data can result in penalties.
Connect review schema to your product schema for maximum impact. This combination enables search engines to display comprehensive product information, including customer ratings, in a single rich result.
Testing and Validation
Use Google’s Rich Result Test to validate your structured data implementation. This tool shows exactly how search engines interpret your markup and identifies errors that prevent rich results from appearing.
Test your structured data after any site updates or template changes have been made. Broken markup can cause rich results to disappear from search listings, reducing your visibility and click-through rates.
Monitor your rich results performance in Google Search Console. Track which pages earn enhanced listings and identify opportunities to expand structured data to more product pages.
Remember that structured data creates opportunities for search result enhancement, but it doesn’t guarantee that rich results will appear. Focus on accurate, complete markup that genuinely helps search engines understand your products and serves your customers better.
Structured Data and Schema Implementation Checklist
- Add Product schema to every product page using JSON-LD format.
- Include required fields in your product schema:
- Name
- Description
- Offers (price, currency, availability)
- Add optional fields to enrich your markup:
- Brand
- Model
- Product identifiers (e.g. SKU, GTIN)
- Use the image property to include high-quality product images in your structured data.
- Implement Review schema with both aggregate ratings and individual reviews.
- Ensure reviews are genuine and match customer feedback displayed on the site.
- Connect Review schema to Product schema for combined rich results.
- Add Breadcrumb schema to reflect your category hierarchy in search listings.
- Use JSON-LD format for all structured data to keep code clean and easy to manage.
- Test your structured data using Google’s Rich Results Test to catch errors and verify eligibility.
- Re-test structured data after any site or template updates to avoid broken markup.
- Monitor rich result performance in Google Search Console to track visibility and identify opportunities.
Crawlability and Technical Optimization
Search engines have limited time to crawl your ecommerce site, making every site visit count. Your crawl budget determines how many pages search engine bots explore during each visit, so you need to guide crawlers efficiently to your most important products and categories.
Charlie Worrall, Digital Marketing Lead at Imaginaire agrees with the above:
“One of the most overlooked aspects of technical SEO for ecommerce is crawl prioritisation. We’ve seen ecommerce sites with thousands of thin or expired category pages that end up bloating the crawl budget and diverting attention from high-value pages.
We always recommend starting with a crawl map and making sure that it follows your priorities. By doing that, your most important category and product pages get crawled and indexed quickly and efficiently. Combine that with structured data, internal linking, and mega-fast page speeds to make sure you’re in a really strong position to scale organic traffic.”
XML Sitemap Strategy
Create focused XML sitemaps that prioritize your money-making pages. Include product pages, category pages, and key landing pages while excluding low-value content such as filtered views or temporary promotional pages. Large ecommerce sites benefit from multiple sitemaps organized by content type.
Update your sitemaps regularly as you add new products or remove discontinued items. Outdated sitemaps waste crawl budget on non-existent pages, delaying the discovery of new content. Automate sitemap generation whenever possible to keep them up to date.
Robots.txt Optimization
Use your robots.txt file strategically to block crawlers from wasting time on duplicate or low-value pages. Block access to search result pages, filtered category views, and shopping cart URLs that don’t provide unique value for search engines.
Include your XML sitemap location in your robots.txt to help crawlers find your most important content quickly. This simple addition guides search engines directly to pages you want indexed while blocking areas that consume crawl budget unnecessarily.
Monitor your robots.txt effectiveness through server logs to ensure you’re blocking the right pages. Accidentally blocking important product categories can significantly harm your search visibility.
Duplicate Content Handling
Canonical tags solve duplicate content issues that can plague ecommerce sites. Product variants, filtered pages, and multiple category paths create similar content with different URLs. Point these duplicates to your preferred version using canonical tags to consolidate ranking signals.
Olga Zhukova, a Freelance SEO consultant, had this to say:
“Be cautious of so-called ‘thin page generators’ – such as language, country, or currency toggles (and their combinations), certain product filters, URL parameters or tags. When misconfigured, these elements can generate a flood of low-value or duplicate pages that are unnecessarily crawled by search engines.
To identify such issues, review the Page Indexing reports in Google Search Console – particularly the ‘Discovered – currently not indexed’ and ‘Crawled – currently not indexed’ sections.“
Use noindex tags for pages you don’t want in search results but need for user navigation. Shopping cart pages, account login areas, and thank you pages serve important functions but shouldn’t appear in search listings.
Handle pagination carefully to avoid duplicate content issues. Use rel=”next” as well as rel=”prev” tags to show the relationship between paginated category pages, or implement canonical tags that point to a “view all” version when practical.
Pagination and Filter Management
Large product catalogs require smart pagination strategies. Ensure search engines can crawl through multiple pages of category listings to discover all your products. Use consistent URL patterns and clear navigation between pages.
Nikhil Sharma had this to say, especially about how Shopify can sometimes fall down on this:
“Faceted navigation improves product discovery for users, but on Shopify, it can quickly lead to crawl bloat and duplicate content if left unmanaged. Every filter combination, such as color or size, can create a new URL with parameters that are crawlable and indexable by search engines. This results in thousands of near-identical pages that dilute authority signals and exhaust crawl budget without adding SEO value.
To address this on Shopify, I recommend implementing a canonical tag that always points to the main category page regardless of the filters applied. This tells search engines to treat all filtered variants as versions of the same core page. In addition, use Liquid in your theme to suppress or remove filter-based parameters from rendering into indexable links. This helps avoid generating unwanted crawl paths.
For an extra layer of control, you can add a nofollow attribute to filter link elements if they do not contribute to unique value or user-generated content.”
Manage faceted navigation to prevent waste of crawl budget. When customers filter products by:
- Color
- Size
- Price
You create numerous URL variations. Use URL parameters wisely and implement canonical tags to prevent these filtered views from competing with your main category pages.
Track which filtered pages provide value and which create unnecessary duplication. Some filter combinations might reveal useful niche categories worth indexing, while others just fragment your content authority.
SSL Implementation
HTTPS protects customer data. Implement SSL certificates across your entire site, not just checkout pages. Mixed content warnings can harm user trust and hinder the proper crawling of secure pages.
Muhammad Hassan Raza, a freelance SEO consultant and content expert, had this to say on web security:
“Website security doesn’t always get the attention it deserves in technical SEO, until something goes wrong. I found that out the hard way when site was hit by a Japanese SEO spam attack. Hackers injected hidden spam pages in Japanese to manipulate search results, and even though regular visitors couldn’t see them, Google could and it hurt our rankings.
I dug in to figure out what happened. Turns out, these attacks often get in through outdated plugins, weak file permissions, or overlooked folders. Cleaning it up meant scanning the site thoroughly, checking the database for injected content, reviewing .htaccess files for cloaking tricks, and using Google Search Console to remove spam from the index.
Since then, I’ve put stronger measures in place: regular malware scans, better file access control, stricter login credentials, and ongoing audits of both our site content and its technical SEO health.”
At the end of the day, technical SEO isn’t just about sitemaps and page speed , it’s about keeping your site secure so your hard-earned traffic and trust aren’t compromised.
Set up proper 301 redirects from HTTP to HTTPS to maintain link authority. Update internal links to use HTTPS URLs and fix any mixed content issues that prevent pages from loading properly.
Monitor your redirects and HTTP status codes regularly through crawl error reports. Broken redirects can waste crawl budget and dilute page authority. Server logs reveal crawling patterns and help identify technical issues affecting search engine access.
JavaScript and Dynamic Content
JavaScript SEO considerations become important when your ecommerce platform relies heavily on dynamic content. Ensure that critical product information is rendered properly for humans and search engines alike.
Crawlability and Technical Optimization Checklist
- Create focused XML sitemaps that include:
- Product pages
- Category pages
- Key landing pages
- Exclude low-value pages from sitemaps (e.g. filtered views, promos).
- Automate sitemap generation to keep them current as products change.
- Add sitemap location to your robots.txt file for easier crawler access.
- Use robots.txt to block:
- Internal search pages
- Filtered views
- Cart and checkout URLs
- Monitor robots.txt performance via server logs to avoid blocking important pages.
- Use canonical tags on duplicate or similar pages to consolidate ranking signals.
- Apply noindex tags to utility pages (cart, login, thank-you).
- Handle pagination properly using:
- rel=”next” and rel=”prev” tags
- Or canonical to a “view all” version if applicable
- Use consistent URL patterns for paginated category pages.
- Implement canonical tags on faceted navigation URLs to prevent duplicate content.
- Evaluate filtered URLs to identify valuable ones worth indexing.
- Enable HTTPS sitewide with a valid SSL certificate.
- Set up 301 redirects from HTTP to HTTPS and update internal links accordingly.
- Fix mixed content issues to avoid crawl or trust problems.
- Regularly monitor redirects and HTTP status codes via crawl reports and logs.
- Ensure JavaScript-rendered content (especially product data) is accessible to both users and search engines.
Platform-Specific Quick Wins
Each ecommerce platform offers unique SEO opportunities you can implement quickly. Utilizing platform-specific features yields faster results than generic optimization approaches.
Shopify
Enable Shopify’s built-in sitemap generation and submit it to Google Search Console. Shopify automatically generates sitemaps for products, collections, and pages, saving you time while ensuring that search engines can easily find your content.
Install SEO-focused apps from the Shopify App Store to automate technical optimizations. Apps like TinyIMG automatically compress images, while SEO Manager handles meta descriptions and structured data across your entire store.
Customize your Shopify theme’s robots.txt file to block low-value pages, such as cart and checkout URLs. Access this through your theme files and add specific directives to prevent waste of your crawl budget.
Use Shopify’s automatic image optimization features for faster loading. The platform supports different image sizes based on device type, but you can further optimize your images by selecting the appropriate file formats and compression levels.
You can set up Shopify’s native breadcrumb navigation feature within your site’s theme settings. This makes the user experience better and provides the structured data that search engines use to better understand your site’s hierarchy.
WooCommerce
Install the Yoast SEO or RankMath plugins, which are specifically designed for WooCommerce. These plugins add product schema markup automatically and provide SEO analysis for each product page, making optimization straightforward.
Enable WooCommerce’s built-in product gallery features for better user experience. Multiple product images improve engagement and provide more content for search engines to index.
Configure WooCommerce’s permalink structure for SEO-friendly URLs. Change the default product base from “product” to something more descriptive, or remove it entirely for cleaner URLs.
Use WooCommerce’s variation handling properly to avoid duplicate content. Set canonical tags for product variations and use noindex for individual variation pages when they don’t provide unique value.
Implement WooCommerce’s native review system to generate authentic user-generated content. Enable review rich snippets through your SEO plugin to display star ratings in search results.
Magento
Configure Magento’s URL rewrites to create clean, descriptive URLs for products and categories. Remove unnecessary parameters and category paths to improve URL structure and user experience.
Use Magento’s layered navigation settings carefully to prevent duplicate content. Configure canonical tags for filtered category pages and use robots meta tags to control which filtered views get indexed.
Enable Magento’s full-page caching to significantly improve site speed. This built-in feature reduces server load, delivering faster page loading for a better user experience and improved search rankings.
Set up Magento’s XML sitemap generation with proper priority settings. Configure separate sitemaps for products, categories, and CMS pages to ensure search engines better understand your content hierarchy and structure.
Optimize Magento’s image handling through the admin panel. Enable image compression and configure responsive image serving to improve page speed across all devices.
BigCommerce
BigCommerce offers powerful built-in SEO features that require minimal setup. Enable the platform’s automatic SSL certificates and CDN integration through your control panel to boost site speed and security without additional configuration.
Configure BigCommerce’s URL structure settings to create clean, keyword-rich URLs. Remove unnecessary category paths and use descriptive product URLs that help both users and search engines understand your content.
Utilize BigCommerce’s native structured data features to automatically add product schema. The platform generates JSON-LD markup for products, reviews, and breadcrumbs, providing rich results without requiring manual coding.
Enable BigCommerce’s image optimization tools to automatically compress product photos. The platform serves responsive images and converts them to modern formats, such as WebP, for faster loading across all devices.
Set up BigCommerce’s built-in blog functionality to create SEO-friendly content. The platform includes proper heading structures and meta tag controls, making it easy to optimize blog posts for search engines.
Configure BigCommerce’s abandoned cart recovery and customer review systems. These features generate user engagement signals and authentic content that search engines value for ranking purposes.
Universal Best Practices
If your store is built on another platform, focus on these universal quick wins.
Implement a proper heading tag hierarchy, using H1 tags for product names and H2 tags for key sections. Use descriptive alt text for all product images to improve accessibility and search visibility.
Optimize your loading speed across all platforms by minimizing your CSS and JavaScript files, compressing images across your site, and enabling browser caching. These improvements work on any ecommerce CMS and deliver immediate performance benefits.
Set up proper internal linking between related products and categories. This helps search engines discover content while improving user experience through relevant product suggestions and cross-selling opportunities.
Create XML sitemaps manually if your platform doesn’t generate them automatically. Include your most important product pages, category pages, and key landing pages to guide search engine crawling efficiently.
Monitor your site’s technical health using free tools like Google Search Console and Google PageSpeed Insights. These platform-agnostic tools identify issues and opportunities that suit any ecommerce site.
Be sure to use basic structured data on custom platforms as well. Product, review, and breadcrumb schema can significantly improve your search visibility, regardless of the CMS you’re using.
Platform-Specific Quick Wins Checklist
Shopify:
- Submit your automatically generated Shopify XML sitemap to Google Search Console.
- Install SEO-focused apps (e.g., TinyIMG for image compression, SEO Manager for meta and schema).
- Customize your robots.txt file to block cart, checkout, and other low-value pages.
- Use Shopify’s image optimization features and select efficient file formats.
- Enable breadcrumb navigation in theme settings to enhance UX and provide structured data.
WooCommerce:
- Install Yoast SEO or RankMath plugin for automated product schema and on-page SEO support.
- Use the built-in product gallery to add multiple images per product.
- Customize your permalink structure to create clean, descriptive product URLs.
- Manage variation content:
- Add canonical tags
- Set noindex on thin variation pages
- Enable WooCommerce’s review system and use SEO plugins to display review rich snippets.
Magento:
- Configure URL rewrites for clean product and category URLs (remove parameters where possible).
- Set up canonical tags and robots meta tags to control indexed filtered views.
- Enable full-page caching to improve load times and reduce server strain.
- Generate XML sitemaps by content type (products, categories, CMS pages) with proper priorities.
- Enable image compression and responsive image delivery in the admin panel.
BigCommerce:
- Enable automatic SSL and CDN features through the control panel.
- Configure URL structure for clean, keyword-rich product URLs.
- Use BigCommerce’s native structured data (JSON-LD for products, reviews, breadcrumbs).
- Enable built-in image optimization and WebP delivery.
- Set up the blog and use correct heading tags and meta tags.
- Turn on abandoned cart recovery and customer reviews to boost engagement and content signals.
Universal Best Practices:
- Use correct heading tag hierarchy (H1 for product names, H2 for sections).
- Add descriptive alt text to all product images.
- Minify CSS/JavaScript, compress images, and enable browser caching for faster loading.
- Create strong internal links between related products and categories.
- Manually create XML sitemaps if needed, prioritizing important product/category/landing pages.
- Monitor technical health with Google Search Console and PageSpeed Insights.
- Add basic structured data (product, review, breadcrumb) even on custom platforms.
If you want to learn and understand more about what ecommerce CMS might be best for you, check out this comparison table below:
Feature/Element | Shopify | WooCommerce | Magento | BigCommerce |
Automatic XML Sitemap Generation | Yes | Via Plugins | Yes | Yes |
SEO Plugin / App Support | Yes | Yes | Limited | Limited |
Customizeable Robots.txt | Yes | Via Plugins | Yes | Limited |
Canonical Tag Support | Limited | Yes | Yes | Limited |
Structured Data Markup | Yes | Yes | Yes | Yes |
Image Optimization Tools | Yes | Yes | Yes | Yes |
URL Structure Optimization | Limited | Yes | Yes | Yes |
Full Page Caching | No | Via Hosting | Yes | Yes |
Built-In Blog Support | No | Via Plugins | Yes | Yes |
Review / Rich Snippet Support | Via Apps | Yes | Via Plugins | Yes |
Internal Linking Enhancements | Manual | Manual | Manual | Manual |
Speed Optimization Tools | Yes | Via Plugins | Yes | Yes |
Monitoring and Measurement
Tracking your technical SEO performance will help you identify issues before they impact sales. You will also have opportunities to enhance your search visibility. Regular monitoring turns your technical optimization from guesswork into data-driven decisions.
Key Technical SEO KPIs for Ecommerce Websites
Organic traffic provides the best measure of technical SEO success. Monitor monthly trends in Google Analytics or Google Search Console to identify any sudden drops that indicate technical issues or steady growth resulting from optimization efforts. You can filter organic traffic by device type to ensure mobile optimizations translate into real traffic gains.
Click-through rate shows how well your pages perform when they appear in search results. A low CTR often indicates problems with:
- Title Tags
- Meta Descriptions
- Missing Rich Snippets
That make competitors more appealing. Track CTR changes after implementing structured data or improving page titles.
Your ranking positions reveal whether technical improvements help your products rank higher. Monitor your most important product categories and brand terms to ensure technical problems don’t cause ranking drops. Sudden position losses often signal crawling or indexing issues.
Search performance data from Google Search Console shows which queries drive traffic to your ecommerce site. Track the growth of impressions for target keywords and identify new opportunities where technical optimizations can capture more traffic.
Page experience report metrics indicate how well your site meets Google’s user experience standards. Monitor Core Web Vitals scores, mobile usability issues, and HTTPS implementation to ensure technical performance supports your rankings.
Essential Tools and Setup
Google Search Console is great for monitoring your ecommerce site’s technical SEO. Set up property verification for both your main domain and any subdomains you use. Submit your XML sitemaps and monitor the index coverage report to ensure search engines can access your most important pages.
Use the URL inspection tool to diagnose specific issues on a page. This tool shows exactly how Google views individual product pages and identifies problems that prevent proper indexing. Test pages after making technical changes to verify improvements work correctly.
Google Analytics provides traffic and conversion data that reveals the business impact of technical optimizations. Set up goals for key ecommerce events, such as purchases and newsletter sign-ups, to measure how technical improvements affect your bottom line.
Monitor your ecommerce site’s crawl stats to understand how search engines interact with your site. If your crawl frequency is increasing, that could mean you’ve improved the technical health of your site. On the other hand, sudden drops could suggest problems that need attention.
Error reports in GSC highlight any technical issues that are affecting your site’s visibility. You should make a point to check these reports weekly for any new:
- 404 Errors
- Server Issues
- Mobile Usability Problems
That could impact your rankings in a negative way.
Ongoing Maintenance and Optimization Strategies
Create a monthly technical SEO review schedule that covers all key areas. Check your index coverage report for new errors, review crawl stats for unusual patterns, and monitor page experience metrics for performance changes.
Set up automated alerts for critical technical issues. Google Search Console can email you when it detects significant increases in crawl errors or drops in indexed pages. Early detection prevents small problems from becoming major ranking disasters.
Track technical improvements over time by documenting baseline metrics before making changes. Record Core Web Vitals scores, page load times, and indexing rates before optimizations, then measure improvements to prove ROI from technical SEO investments.
Audit your technical SEO quarterly using a comprehensive checklist. Review robots.txt settings, XML sitemap accuracy, canonical tag implementation, and structured data markup to catch issues that develop gradually over time.
Focus your optimization efforts on pages that drive the most traffic and revenue. Use Search Console data to identify your highest-performing product pages and categories, then prioritize technical improvements for these money-making areas first.
Connect technical metrics to business outcomes by analyzing how technical improvements affect conversion rates and revenue. This data helps justify continued investment in technical SEO and guides future optimization priorities.
Monitoring and Measurement Checklist
- Monitor organic traffic monthly in Google Analytics and Google Search Console
- Filter organic traffic by device type to assess mobile performance
- Track click-through rates and improve low performers with better titles, meta descriptions, or structured data
- Monitor ranking positions for key product categories and brand terms
- Track impressions and query data in GSC to find new growth opportunities
- Review Core Web Vitals, mobile usability, and HTTPS coverage in the Page Experience Report
- Verify your main domain and subdomains in Google Search Console
- Submit your XML sitemap and monitor index coverage reports weekly
- Use the URL Inspection Tool to test technical fixes and confirm indexing
- Track traffic and conversions in Google Analytics to measure business impact
- Monitor crawl stats in GSC to understand how bots interact with your site
- Check error reports weekly for 404s, server issues, and mobile usability problems
- Perform a monthly technical SEO review (index coverage, crawl stats, page experience)
- Set up GSC email alerts for crawl issues or sudden drops in indexed pages
- Record baseline metrics (e.g. Core Web Vitals, indexing rates) before making changes
- Measure results post-optimization to track technical SEO impact
- Audit technical SEO quarterly (robots.txt, sitemap, canonicals, structured data)
- Prioritize fixes on pages with the most traffic and revenue
- Analyze how technical improvements affect conversion rates and sales
Technical SEO for Ecommerce Websites: Frequently Asked Questions
What is technical SEO for ecommerce sites?
Technical SEO ensures that search engines can:
- Crawl
- Understand
- Index
Your ecommerce site efficiently. It covers areas like site speed, structured data, mobile usability, and URL structure. This all helps your products appear in search results and improves the experience that customers have on your ecommerce site.
Why is technical SEO important for ecommerce websites?
Often featuring thousands of pages, and sometimes even hundreds of thousands, ecommerce sites are vulnerable to:
- Crawl inefficiencies
- Duplicate content
- Poor mobile performance
Technical SEO fixes these issues and ensures your ecommerce site ranks well in search, leading to more traffic and more sales.
How often should I audit my ecommerce site’s technical SEO?
At minimum, you should perform a technical SEO audit every quarter. However, you could check crawl errors, index coverage, and page experience metrics monthly. Especially if you’re adding new products or making site changes regularly!
Which pages should I prioritize first?
Start with your homepage, main category pages, and best-selling product pages. These drive the most traffic and revenue, so optimizing them first delivers the biggest ROI.
What tools should I use to monitor my ecommerce site’s technical SEO?
Use Google Search Console, Google Analytics, PageSpeed Insights, and tools like Lighthouse for regular analysis. These are free and give you actionable data on crawlability, indexing and performance.
Does technical SEO guarantee better rankings?
No SEO tactic can guarantee better rankings. But technical SEO gives your site the best possible foundation. It ensures search engines can access and understand your content, which is the prerequisite for ranking improvements.
How can I test if my technical SEO changes actually work?
Use tools like SEOTesting to run controlled tests. Test changes like page speed improvements, structured data implementation, or mobile updates to see their impact on rankings, CTR, and conversions.
Wrapping Things Up
Technical SEO creates the foundation that turns your ecommerce website into a sales-driving machine. When search engines can easily:
- Crawl
- Understand
- Index
Your products and categories, more customers will find your site through organic search.
Start with these quick wins, before anything else:
- Make your site architecture better.
- Improve your page speed.
- Implement missing structured data.
Remember that technical SEO is an ongoing task that requires constant attention. It’s never a one-time fix. Monitor your performance monthly, address issues promptly, and continually optimize your highest-traffic pages. The ecommerce businesses that prioritize technical SEO may consistently outrank and outsell their competitors.
Technical SEO optimization is only half the battle. Which changes actually drive revenue for your ecommerce website?
SEOTesting helps you prove ROI through controlled tests. Test page speed improvements, structured data implementations, and site architecture changes to see what really works.
✅ Measure Core Web Vitals’ impact on conversions.
✅ Track structured data impacts on click-through rates.
✅ Validate mobile optimizations against organic traffic.
Stop guessing. Start testing.
Start your 14-day free trial →
No credit card required!
Testimonials
-

"Can totally recommend! It’s not only full of reports to easily identify low hanging fruit opportunities but also, the most straightforward platform to help run SEO tests"
Aleyda Solis, Intl SEO Consultant, Speaker & Author.
-

"SEOTesting has become one of my go-to SEO tools because it does so much with all the valuable data hidden in Google Search Console. It's the only thing that gives us the ability to use that data for keyword tracking, SEO tests, and quality testing."
Ruben Gamez, DocSketch