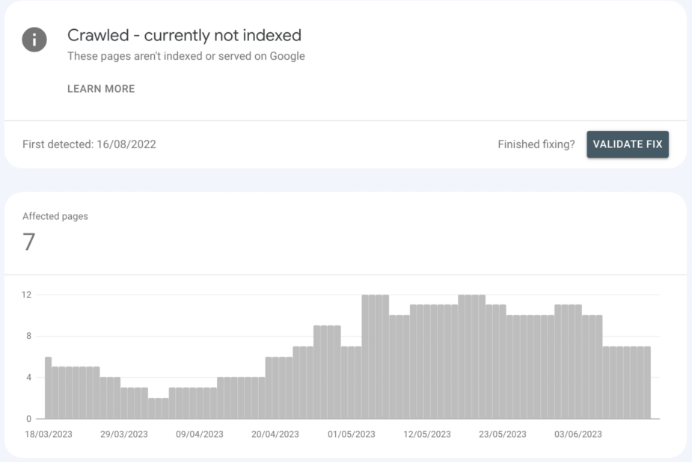
Crawled – currently not indexed is an excluded status used in Google Search Console. It’s used to denote that Google has crawled a page but decided not to index it. This means the URL will not appear on the SERPs.
Google does not publicly explain the exact criteria used to apply this status. However, based on industry testing, documentation, and observed patterns, pages commonly receive this status when Google’s systems determine they do not currently provide sufficient value to justify indexing. This article will focus on how to fix the Crawled – currently not indexed GSC error code. This article is part of our Google Search Console tutorials and training section. Be sure to check the other articles out.
Crawled – Currently Not Indexed: Quick Summary (TL;DR)
Crawled – currently not indexed is an excluded status in Google Search Console that means Google has crawled a page but chosen not to include it in the search index.
This usually happens when Google identifies limited standalone value in the page, such as:
- Weak or missing internal links (orphaned pages)
- Thin or low-quality content compared to competing results
- Search intent mismatch
- Near-duplicate content without proper canonicalization
- Structured data errors
- Out-of-stock or expired ecommerce products
- Private, gated, or unintentionally accessible URLs
- Pagination or RSS feed URLs that are not intended to be indexed
Fixes focus on improving content quality, strengthening internal linking, matching search intent, resolving duplication, and cleaning up technical signals like structured data, redirects, and access controls.
Not every case requires action—some URLs are intentionally excluded by Google. The key is deciding whether a page should be indexed, then aligning content and technical signals to justify inclusion.
Definition: What the Crawled – Currently Not Indexed Status Means in Google Search Console
The Crawled – currently not indexed status means that Google has crawled your page but made a deliberate decision not to add it to the search index. This means the page will not show up on Google’s SERPs for any query. This decision can occur for multiple distinct reasons, which are covered below.
How to Fix Crawled – Currently Not Indexed: Common Causes and Fixes
Below is a list of common issues that can cause Google to label pages as Crawled – currently not indexed. We have also listed practical solutions you can use to increase the likelihood of indexing. It’s worth noting the Crawled – currently not indexed status is different from the Excluded by ‘Noindex’ tag status. In both cases, Google has crawled the page and chosen not to index it, but Crawled – currently not indexed indicates a quality or relevance-based decision rather than an explicit directive.
Improve Internal Linking
Google may choose not to index a page due to weak internal linking or a lack of clear contextual signals. Pages without any incoming internal links are commonly referred to as orphan pages. To resolve the Crawled – currently not indexed status, improve internal linking. You can improve your internal linking by:
- Finding an existing page on your site that already performs well in search.
- Identifying sections that are topically relevant to your non-indexed page.
- Adding relevant and descriptive internal links to your non-indexed content.
You can also find internal linking opportunities through this Google search modifier: Site:yourdomain.com ‘target keyword of non-indexed page’. This search finds pages on your site that already mention your target keyword, making them strong candidates to link to your non-indexed content. Internal linking signals importance and relevance to Google. This fix can often be implemented quickly, but it can significantly improve indexation outcomes.
Thin or Low-Quality Content Causing Crawled – Currently Not Indexed
Pages with limited depth or incomplete coverage may be crawled but excluded from the index because they do not sufficiently satisfy user needs. Thin content typically occurs when a page provides substantially less information than competing results. For example, if top-ranking pages comprehensively cover a topic, a significantly shorter page may struggle to justify indexing. Review competing pages to understand expected coverage and expand your content where needed. Focus on usefulness and completeness rather than word count alone.
Search Intent Mismatch Leading to Crawled – Currently Not Indexed
Search intent mismatch can cause Google to crawl but not index pages when the content format or focus does not align with user expectations. For example, for “how to calculate taxes,” Google may surface guides and videos, while “tax calculator” primarily returns tools. Review first-page Google results before creating or revising content. This helps identify the content type Google prefers. To fix Crawled – currently not indexed pages, update your content to better match the dominant search intent.
Near-Duplicate Content Preventing Pages from Being Indexed
Google avoids indexing multiple pages that provide substantially similar content, even though duplicate content does not result in penalties. Pages with high content overlap often receive the Crawled – currently not indexed status. Duplicate content commonly occurs in these situations:
- Ecommerce sites with similar product variations
- Sites with large volumes of user-generated content
- Pages targeting closely related topics
Google filters similar pages to improve search quality. Review your Performance report to identify which pages already rank for the target query. Apply canonical tags where appropriate to signal the preferred version. If pages serve different purposes, revise content to ensure each page provides distinct value.
Structured Data Errors That Lead to Crawled – Currently Not Indexed
Structured data helps search engines understand page context. Errors in structured data can create ambiguity about page purpose, which may contribute to exclusion after crawling. Check the Enhancements section in Google Search Console to identify errors. Pages with warnings may still be indexed but may miss enhanced search features. Fixing structured data issues improves Google’s ability to interpret and index the page.
Out-of-Stock or Expired Products Causing Crawled – Currently Not Indexed
A common issue on ecommerce sites involves product pages that remain unavailable for extended periods. These pages may appear as Crawled – currently not indexed because Google aims to avoid surfacing unavailable products in search results. Review product availability signals and ensure they accurately reflect current stock status. After correcting availability issues, request a recrawl. John Mueller from Google provides guidance on this scenario.
When 301 Redirects Result in Crawled – Currently Not Indexed
This issue is uncommon but can occur, particularly on sites with frequent URL changes. In some cases, redirect destination URLs appear in the Page Indexing Report as Crawled – currently not indexed due to crawl prioritization rather than redirect errors. Creating a temporary sitemap containing the affected URLs can help Google reassess and index them more efficiently.
Private or Gated Content Appearing as Crawled – Currently Not Indexed
Googlebot can sometimes crawl URLs that are technically accessible but not intended for public indexing. This commonly includes development environments, login-protected areas, and paywalled content. This typically happens when crawl paths are unintentionally left open. To prevent this:
- Run a website crawl using ScreamingFrog or Sitebulb
- Create a list of URLs that should remain private
- Apply appropriate controls:
- Remove internal links to these pages
- Remove them from XML sitemaps
- Block crawling via robots.txt where appropriate
These actions prevent private content from appearing as Crawled – currently not indexed and reduce the risk of unintended exposure.
Additional Causes of Crawled – Currently Not Indexed (Edge Cases)
False Positives: When Crawled – Currently Not Indexed Pages Are Actually Indexed
A false positive occurs when Google Search Console reports a page as excluded, but the page still appears in search results. To verify this:
- Go to Google.com
- Search for the full page URL
- Confirm whether the page appears in results
If the page appears despite the Crawled – currently not indexed status, no action is required. The issue exists in Search Console reporting rather than actual indexation.
Paginated URLs That Google Crawls but Doesn’t Need to Index
Pagination is commonly used on blogs and ecommerce sites to organize content. Paginated URLs, such as /page/2/, are often crawled but intentionally excluded from the index. Before attempting fixes, assess whether these pages provide standalone search value. Review Google’s pagination best practices and relevant SEO guidance before taking action.
RSS Feed URLs Marked as Crawled – Currently Not Indexed (and Why That’s Ok)
RSS feeds are designed for syndication, not search results. If Google crawls but does not index RSS feed URLs, no action is required.
Crawled vs Discovered – Currently Not Indexed: Key Differences for Troubleshooting
These two statuses differ primarily by crawl activity. Discovered – currently not indexed means Google found the URL but has not crawled it yet. Crawled – currently not indexed means Google has crawled and evaluated the page but chose not to include it in the index. The distinction matters for troubleshooting, as each status requires different corrective actions.
Crawled – Currently Not Indexed FAQs: Causes, Fixes, and Best Practices
What does Crawled – currently not indexed mean in Google Search Console?
In Google Search Console, Crawled – currently not indexed means Googlebot has visited your page, analyzed its content, and decided not to include it in Google’s search index. As a result, the page will not appear in search results for any query.
Is Crawled – currently not indexed bad for SEO?
Not necessarily. This status is not a penalty. It indicates that Google does not currently see enough value in indexing the page. If the URL is important for traffic or conversions, it is worth investigating. If it serves a low-value or duplicative purpose, exclusion may be expected.
Why are my pages crawled but not showing in Google?
The most common reasons include:
- Weak or missing internal links
- Thin, low-quality, or unhelpful content
- Search intent mismatch
- Near-duplicate content without a clear canonical
- Structured data errors or conflicting signals
Google crawls the page successfully but chooses not to index it because another page better satisfies user intent.
How do I fix Crawled – currently not indexed pages?
Focus on quality and clarity rather than forcing indexation:
- Improve internal linking so the page is clearly connected to relevant indexed content
- Expand or refine content to fully satisfy search intent
- Resolve duplication with canonical tags or consolidation
- Fix structured data errors if present
- Ensure the page provides genuine standalone value
Should I request indexing or wait?
Request indexing only after meaningful changes are made. Requesting indexing without improvements rarely results in faster inclusion and can delay reassessment.
How long can pages stay in Crawled – currently not indexed?
Pages can remain in this state for weeks or months. Some resolve automatically as Google reassesses site quality and internal linking, while others remain excluded if value signals do not change.
What’s the difference between Crawled – currently not indexed and Discovered – currently not indexed?
- Discovered – currently not indexed: Google knows the URL exists but has not crawled it yet
- Crawled – currently not indexed: Google has crawled and evaluated the page but chose not to index it
Can canonical tags, noindex, or robots.txt cause this status?
Indirectly, yes. Conflicting canonical signals, accidental noindex directives, or unclear crawl instructions can contribute to exclusion after crawling. Always verify indexing signals using the URL Inspection tool.
When should I leave a page as Crawled – currently not indexed?
If the page:
- Has no realistic organic traffic potential
- Duplicates another page’s purpose
- Exists only for navigation, filtering, pagination, or internal use
…then leaving it unindexed is often the correct outcome.
Testimonials
-

"Can totally recommend! It’s not only full of reports to easily identify low hanging fruit opportunities but also, the most straightforward platform to help run SEO tests"
Aleyda Solis, Intl SEO Consultant, Speaker & Author.
-

"SEOTesting.com has become one of my go-to SEO tools because it does so much with all the valuable data hidden in Google Search Console. It's the only thing that gives us the ability to use that data for keyword tracking, SEO tests, and quality testing."
Ruben Gamez, DocSketch