If you have come across the ‘Discovered – currently not indexed’ error within Google Search Console, you will know and understand how frustrating this is for marketers, webmasters and business owners.
In this article, we will give you all the information you need to know about this error code. We will tell you what it is, what the reasons for the code being displayed are as well as what you should do in order to remove this error code and get Google indexing your URLs correctly.
Reading this article and following this advice will be a great first step into getting your URLs indexed, and therefore ranked, by Google. Leading to, in the end, bringing more organic traffic into your business.
If you are, instead, seeing the ‘Crawled – currently not indexed‘ error code, you should check out our article on that topic, as the reasons for seeing this code and the fixes are slightly different.
This article makes up part of our Google Search Console tutorials and training series. Make sure to check out the other articles in this series to build your knowledge on Google Search Console and how to use it to its full potential.
What is the “Discovered – currently not indexed” error?
The ‘Discovered – currently not indexed’ error code is a status from the Google Search Console coverage report. You will find any instances of the code appearing here:
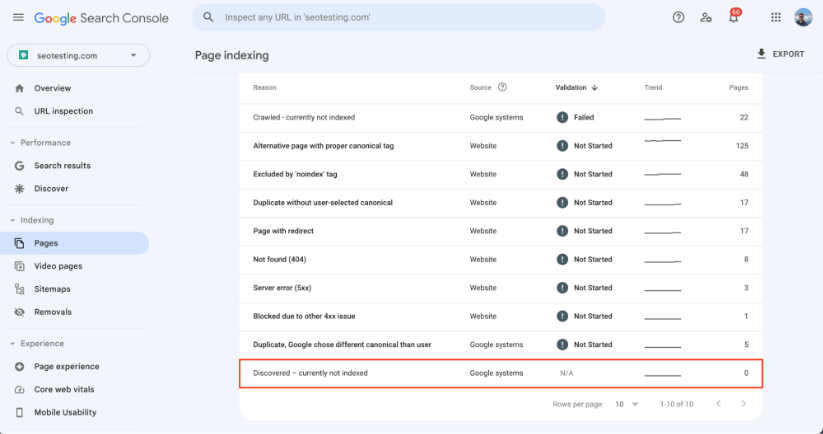
This code is, in fact, one of the most common Google Search Console error codes seen by marketers and webmasters. This status is used when Google knows a page exists, but has not crawled or indexed it yet.
Google can discover pages via XML sitemaps, internal links and external links from other websites.
Why is it taking time to get my pages crawled by Google?
The frequency that Google crawls a website varies, explaining why it might take more time to crawl your pages.
Some factors that influence how frequently Google crawls a website are:
How relevant Google considers the website.
If you are not publishing content that is relevant to your website and business, there is a high chance that Google is not going to index and rank your content. Therefore, you may see the ‘Discovered – currently not indexed’ error code displayed.
For example, if you are an SEO agency and you start publishing content around venture capital and investing in companies, unless you do this as a business practise (and this is well documented) then Google may not choose to index this content, even if it has discovered your URLs via your sitemap or internal links.
Always ensure the content you are pushing out matches the search intent of the queries you are targeting.
How frequently the website publishes new content.
It is no secret that Google loves fresh content, and websites that publish content on a regular basis. If you are website that does not release content on a regular basis, you may find your content takes longer to index than other websites. Whilst waiting for your content to be indexed, you may find this error occurring. Google knows your content exists, but it is delaying crawling and/or indexing as your website does not publish content regularly.
You do not need to have a regular publishing cadence, for example weekly or monthly, but you do need to ensure you are regularly publishing fresh content, as well as updating pages that have been left stagnant for a while. You can remind yourself to do this as part of an SEO checklist. We also have a content refresh standard operating procedure to help with this, free for you to use for your business!
You may even consider using AI tools to help you improve the frequency at which you publish and/or update content on your website.
The speed of the website and its servers.
Ever since CWV (Core Web Vitals) became a ranking factor, Google has placed a larger focus on how quickly websites can serve users with the content they have asked for.
Because of this, you will find that quicker websites get their content indexed quicker. Slower websites may see more of a delay in getting their content indexed and ranked. If you have a consistently slower website, you will more than likely see a delay between Google discovering your content and crawling and/or indexing it.
Having too many URLs to crawl on the website.
This is a potential cause that will only impact large websites, with thousands, hundreds of thousands or even millions of URLs.
Google crawlers operate on ‘crawl budget’. This means each website has a certain allowance for how many times their pages are crawled within a certain timeframe.
If you have an extremely large website and are having issues managing your crawl budget, Google will delay crawling and indexing certain pages until you have the crawl budget to allow for it.
This is a common problem for news websites that are uploading hundreds or even thousands of new pages every single day.
Errors on the site, wasting crawl budget.
If you have a large website, its important to keep your crawl budget in check.
Having multiple errors, such as inactive webpages, keyword cannibalization issues, issues with your server, etc can impact your website’s crawl budget, meaning new content you publish may see a delay in being crawled and indexed by Google. Whilst these crawl issues are impacting your website, you are likely to see the ‘Discovered – currently not indexed’ error.
Discovered – Currently Not Indexed is different to other error codes such as the “Excluded by ‘Noindex’ Tag” error. Whilst this means your page has been crawled but has not been indexed due to a noindex tag appearing somewhere in the sitemap or on the page, the Discovered – currently not indexed error means Google has not chosen to crawl your page at all.
Why does Google exclude some pages from indexing?
It’s impractical or even impossible to index every page on the web, so you can’t necessarily expect Google to index all the pages of any website, including yours.
Over the years, Google has developed content guidelines to deal with the ever-growing number of pages. They work as a way for Google to determine what they should index.
Here is a list of common situations causing Google to not index pages:
Technical reasons.
Sometimes, pages are not accessible by humans are removed completely from Google’s index. This will include pages with errors (denoted by 4xx codes) and redirects (denoted by 301 and 302 error codes).
If Google regularly comes across pages with errors or redirects, they are more than likely to stop indexing these pages. They know the page exists (hence, they have discovered) the page but they will refuse to index and rank it, explaining the ‘Discovered – currently not indexed’ error code displaying on your page indexing report.
Lack of crawl budget.
As we discussed earlier, large pages will have to effectively manage their crawl budget.
Once a website has exceeded its crawl budget, Googlebot will place new pages published on a ‘waiting list’ to be crawled, indexed and ranked. You will need to wait for your crawl budget to have space before Googlebot returns to crawl these pages.
Pages that are excluded by design.
Sometimes, it’s completely natural for a website owner to not want a page to be indexed. If this is the case, the most common way to denote this to Google is to use the robots.txt file or a noindex tag on the page itself.
This also happens to pages with a canonical tag that refers to a different URL.
Sometimes, you will see other error codes if this is the case, including:
- URL – blocked by robots.txt
- URL marked ‘noindex’
- Alternate page with proper canonical tag.
Although, in other cases, Google will display the ‘Discovered – currently not indexed’ error code instead.
Poor website structure.
If your website has a poor or generally confusing structure, Google’s crawler (Googlebot) might struggle to navigate and understand the content hierarchy. This will result in delayed indexing.
A well-organised website structure, with clear internal linking and a proper page hierarchy will help search engines better understand and comprehend your site’s layout and content relationships. This will facilitate a smoother indexing process.
Google saving resources.
Google will sometimes evaluate websites periodically to ensure they are being as efficient as possible with their crawling resources.
If a page is “Discovered – currently not indexed” then it could be due to factors like:
- Low quality/Thin content content.
- Duplicate content.
- Pages with minimal relevance.
Google will postpone indexing to focus resources on more valuable or unique content.
To address this, enhance the content quality and uniqueness of the pages you are struggling to get indeed and ensure it aligns with Google’s indexing criteria to improve its chances of being indexed, and indexed quickly.
Sometimes, Google can simply decide a page is not worth the effort to crawl due to one of the reasons above.
In the words of Google Search Advocate John Mueller:
“There’s no objective way to crawl the web properly. It’s theoretically impossible to crawl it all, since the number of actual URLs is effectively infinite.”
How to fix ‘Discovered – currently not indexed’
As has been seen above, there are many reasons why Google might not be crawling pages on your site. But now it’s time to focus on what you can do to fix this dreaded ‘Discovered – currently not indexed’ status.
Fix 1) Manually ask Google to crawl the page.
If you published a page some time ago and Google hasn’t crawled it, it’s time to manually ask them to crawl the page.
To request Google to index a page, follow these steps:
- Use the URL inspection tool on Google Search Console (on the sidebar or top of the page);
- Put the URL you want Google to crawl;
- Press Enter (or Return) and wait for the URL report;
- Click on “Request Indexing” for Google to put this URL on their crawl queue.
An important reminder is that you should only do the process 1 time. Repeatedly pressing “Request Indexing” won’t make Google crawl the page faster.
Doing the steps mentioned below in this guide is important as Google should be finding and crawling pages on your site without you having to ask manually every time. If they don’t, there’s likely something wrong with your site, or it needs improvement.
It’s also worth asking Google to manually crawl after any SEO test in which a page (or pages) has been changed. This is simply good practice.
Fix 2) Check server capacity.
Check if your website servers are handling Google crawlers without getting overloaded.
Check the crawl stats on Google Search Console or the crawl logs on your hosting server.
To access server health, look at the average response time and 5xx error codes (overloaded server). You don’t have to do anything if the server is not experiencing these errors. But if you find those 5xx errors, consider upgrading your web hosting infrastructure or improving the website performance.
Fix 3) Check if the page is in the XML sitemap.
Google can discover and index pages that aren’t in XML sitemap files, but it is recommended to include them anyway. This way, you signal it’s a relevant page that you want to index and make it easier for crawlers to find it.
A potential solution for WordPress users is to use a WordPress plugin that updates XML sitemap files automatically when new pages are published. Popular options are Yoast, Rank Math, and SEOPress.
For other website builders and CMSs, check if there is an existing XML sitemap or if you need to create one. Typically, you can find a sitemap if you add “sitemap.xml” after the root domain. For example, example.com/sitemap.xml.
Fix 4) Create a temporary sitemap.
Sometimes even if you already have an XML sitemap, it may help with the crawling and indexing of new pages to create a temporary XML sitemap containing just the URL you wish to get into the search results. This is one of the tips in our guide about getting content index quickly by Google. Check it to improve your website indexing speed.
Fix 5) Optimize Google crawl budget.
The lack of crawl budget is another factor that affects pages getting crawled. Usually, only big websites with tens of thousands of pages have to worry about crawl budget.
However, if your site is in that category or you are facing issues getting content indexed, these are the steps to optimize crawl budget:
- Fix crawl errors such as broken internal pages that produce 404 errors.
- Fix internal links that 301 redirect to another internal page.
- Remove redirect chains (also known as redirect loops) because they eat crawl budget;
- Block parts of your website to avoid Google from crawling pages you consider less relevant (only for advanced SEOs);
- Optimize website speed by reducing image sizes, minimizing HTTP requests, and minifying CSS and JavaScript.
Even if your website doesn’t suffer from crawl budget issues, it’s worth improving the website speed as it is a Google ranking factor.
The “Discovered – currently not indexed” error, found within your page indexing report on Google Search Console, can be a frustrating challenge for marketers, webmasters and business owners.
This article has provided comprehensive insights into the causes of this error, ranging from the relevance of the website and publishing cadence to website speed and crawl budget management. We’ve also gone in-depth on how you can solve the issue for your website, no matter the size or your budget.
If you are interested in taking your usage of Google Search Console to the next level, consider giving SEOTesting a try. A SaaS solution for businesses to improve organic search traffic through the medium of SEO testing, we also have a number of useful reports to help you make the most out of the data from your GSC account.
We currently have a 14-day free trial for you to test out the software. So give it a try today!
Testimonials
-

"Can totally recommend! It’s not only full of reports to easily identify low hanging fruit opportunities but also, the most straightforward platform to help run SEO tests"
Aleyda Solis, Intl SEO Consultant, Speaker & Author.
-

"SEOTesting.com has become one of my go-to SEO tools because it does so much with all the valuable data hidden in Google Search Console. It's the only thing that gives us the ability to use that data for keyword tracking, SEO tests, and quality testing."
Ruben Gamez, DocSketch