Google Search Console is one of the most widely used tools within the search marketing community. It is especially helpful when looking at the status of pages in terms of Google’s three key systems:
- Crawling
- Indexing
- Ranking
With this article, we are going to specifically focus on Google’s crawling and indexing stages. More specifically, we are going to cover the different errors you may find within your Google Search Console coverage report. More importantly, we’ll give you information on how to fix them.
You will see all of your warnings and errors within Google Search Console within the Page Indexing report. It will look something like this:
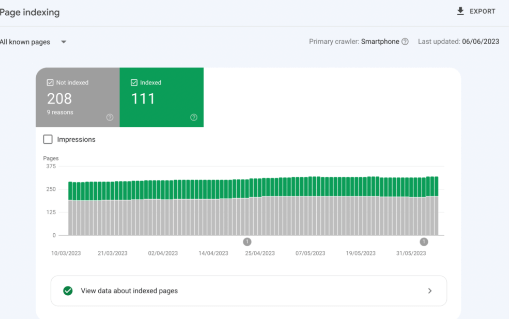
Note: We don’t have any warnings or errors on this particular website. If we did, it would show as an orange box for warnings and a red box for errors.
Here’s the list of errors and warnings you can come across within Google Search Console. We haven’t shown other errors, like the “No Referring Sitemaps Detected” error code, as this article is only going to cover indexing issues. We will write another article soon on the other error codes found within Google Search Console.
- Not Indexed
- Server error (5xx)
- Redirect error
- URL blocked by robots.txt
- URL marked ‘noindex’
- Soft 404
- Blocked due to unauthorised request (401)
- Blocked due to access forbidden (403)
- Not found (404)
- URL blocked due to other 4xx issue
- Blocked by ‘Page Removal Tool’
- Crawled – Currently Not Indexed
- Discovered – Currently Not Indexed
- Alternate page with proper canonical tag
- Duplicate without user-selected canonical
- Duplicate, Google chose different canonical than user
- Indexed, with Warnings
- Indexed, though blocked by robots.txt
- Indexed
Server error (5xx)
If Google is presenting you with a server error, it means something is stopping their crawler, Googlebot, from accessing the page to crawl and rank it. There are, generally, three different types of server errors.
500: 500 is an ‘internal server error’ which means that technical issues are causing the server to delay processing the request. This could be down to several reasons. There could be a coding issue within your CMS, improper PHP code on your website or another reason entirely.
502: 502 errors signify ‘bad gateway’ errors. This means your request has been delayed due to an upstream service not responding. The upstream could be running on the same machine or a different machine entirely. Generally, if you are presented with a 502 error, it is an error with your CMS like WordPress.
503: 503 errors are ‘service unavailable’ errors. This means that the server is too busy, down for maintenance or down entirely and it is taking too long for Googlebot to access the site. Googlebot only waits a certain amount of time before it gives up and presents a 5xx error.
To fix this issue so Googlebot can crawl your site, you first need to establish whether the server error is a 500 error, a 502 error or a 503 error. This is something your IT department/staff can help with.
Redirect error
Google will occasionally run into problems with redirects on your website. This is one of the most common errors presented by Google Search Console. Luckily, they are generally the easiest ones to fix.
There are a few different types of redirect errors:
Redirect loops: A redirect loop is a redirect chain that ends in the original URL that you wish to redirect, starting the chain again. If for example, I wanted to redirect https://www.website.com/originalURL to https://www.website.com/redirectedURL but, within the chain, I ended up on the original URL again, Google would head back to this URL and the chain starts again.
Redirect chains that are too long: We talked earlier about the fact that Googlebot gives up if a server takes too long to respond. It’s the same when it is dealing with a redirect chain. If the redirect chain is too long, and it takes Googlebot too long to reach the final URL, it will give up and throw an error.
‘Bad’ or empty URLs within a redirect chain: If there is a URL that does not work, for any reason, within a redirect chain, Googlebot will throw an error. This could be a 404 (which we will talk about later) or an empty URL. It doesn’t matter. If Googlebot cannot access a URL within a redirect chain, this error will be given to you.
The redirect URL exceeded the max character length for a URL: Simply put, URLs have a character length that they need to stick to. If this happens, Googlebot will not crawl this URL and you will see an error. You should always ensure to shorten your URLs where possible.
To fix a redirect error, whatever the cause, you need to find the original redirect URL and the final URL. In Leyman’s terms, you need to find the URL that you want to redirect and the URL that you want to redirect that URL to. You can do this using a site crawling tool like ScreamingFrog or Sitebulb. These also have handy tools within them to help you with redirect errors. Using these tools will allow you to see and clean the entire redirect path. If you can, try and keep any redirect chains to a minimum and have one URL redirecting to the final URL for ease. If you are interested, we have a handy guide on how to fix redirect errors within Google Search Console.
URL blocked by robots.txt
If you are being presented with a URL blocked by robots.txt error, it means Googlebot is being stopped from accessing a certain page, or pages, on your website by your website’s robots.txt file. Essentially, your robots.txt file is stopping Googlebot from crawling the page.
There are two common reasons for this happening. Firstly, you may have incorrectly configured your robots.txt file. You may have accidentally blocked Googlebot from accessing a certain page. This can happen a lot in WordPress if you have SEO plugins like Yoast or RankMath. It also may be a case that you have included a disallow directive in your robots.txt file, and it is this directive that is stopping Googlebot from crawling your page.
To fix this, you should download a copy of your robots.txt and run a search for the URL that is being blocked. It may be a case that the entire URL is in there, if this is the case, then this will show after running the search. If your full URL does not show up, try a prefix as it may be the case that your robots.txt file is blocking a URL section that includes this page. Once you have found your page in your robots.txt file, you can remove it and re-upload the file.
URL marked ‘noindex’
If you are seeing a URL marked ‘noindex’ error, it means that Google has identified a page you’d like to be indexed (most likely because it is featured in your website’s sitemap or as an internal link on your website) but something is stopping Google from indexing the page.
There are two likely causes for this. Either a noindex meta tag within the page’s HTML or an X-Robots-Tag HTTP header. Googlebot will have seen these and not be able to index your page.
If you have come across this error, take a look at your page’s source code and see if you can spot either the noindex meta tag or the X-Robots-Tag showing noindex and remove this. Resubmit the URL through Google Search Console and you should be good to go.
Soft 404
A soft 404 error is a confusing one. Essentially, it shows users a page signifying it is a 404 page and that it is not available, but at the same time, it is returning a 200 code to the browser. Googlebot sees this 200 code, but at the same time sees what is being shown to users, and that it cannot possibly offer any value. Because of this, it does not index the page and you are given an error.
There are a couple of reasons for this. It mainly happens when you are using a CMS like WordPress. When you create a tag within WordPress, a new URL is automatically created which Google could find. Especially if it is automatically added to the sitemap. Googlebot will see this, and crawl it (due to it being a working URL) but it will see that there is no content. It decides that this is not useful for the user and throws this error.
If this happens, you should first find out why users are being shown a page with no information (easy to do if it is the tag issue with WordPress as mentioned above) and fix it by removing the URL entirely or adding useful content to the page and removing any 404 wording from the page.
Blocked due to unauthorised request (401)
If you are coming across the blocked due to unauthorised request error, it means Googlebot is being blocked from accessing the page to crawl, index and rank it. This can happen whether users can access the page without issue or not.
The most common reason this error is shown is that your website is blocking Googlebot from crawling the page, most likely down to your firewall or internal site systems blocking Googlebot. This can also happen during site crawls. If you are not allowing a site crawler (such as ScreamingFrog or Sitebulb) then you will see a similar error.
To fix this issue, you need to find out why Googlebot is being blocked and remove the block. You can often do this by heading into your firewall settings.
Blocked due to access forbidden (403)
When you are presented with a 403 status code on a website, there are three possible reasons for this:
- Your server understood the request and it knows where the page can be found.
- Browsers (or crawlers) making the request need permission to access that specific page.
- Your server denied the request because the presented credentials did not warrant granting the right permission.
When Googlebot visits a page to crawl it, it does not provide any access credentials while making a request. If you see a 401 code, you know it is because Googlebot wasn’t granted the right permissions as we have gone over above.
If you see a 403 code, it could be down to the following reasons:
- Errors in your .htaccess file. In this case, you should deactivate this faulty file and create a new one.
- Faulty WordPress plugins. If this is the case, you should deactivate your plugins one by one until you find the plugin causing the 403 error and then reinstall the plugin to the newest version to see if this fixes the problem.
- Wrong IP address. If your domain name points to the wrong IP address, a 403 error may occur. Verify your A record with your domain provider to fix this issue.
- Malware infection. If none of the above are the reasons for your 403 errors, you may have been infected with malware. If this is the case, scan your website for signs of an infection.
Not found (404)
If you are presented with a 404 error within your Google Search Console report, it means Googlebot has tried to crawl a URL that does not exist anymore.
We talked about the ‘soft’ 404 error a little earlier, but this is a little more permanent. It means the URL has been changed and no redirects have been implemented, or it means the URL simply does not exist anymore.
If you are being presented with this error code, you should first run a crawl of your website and analyse your sitemap to find instances where the old URL is showing up. Once you have found these, you can delete the URLs from your website and sitemap if they have indeed been removed from your site.
If this error is being thrown due to an old URL not having redirects in place, you need to ensure redirects are put in place before re-crawling the URL via Google Search Console. You can do this manually, or by using a plugin such as Yoast or RankMath if you use WordPress.
URL blocked due to other 4xx issue
Sometimes, Googlebot is presented with a 4xx code but it cannot quite determine what code it is. In this case, the URL blocked due to another 4xx issue is given to you. You first need to determine which code is being given by visiting the URL manually.
- 404 error. As we spoke about just above, this means Googlebot has tried to crawl a URL that does not exist anymore.
- 400 error. The 400 error is thrown when a server is unable to process the request. Mainly due to a website being down for maintenance or if there is an error in the page’s code.
- 403 error. This error is thrown when the website is restricted from being accessed. Is the website password protected or protected behind a paywall?
Once you have correctly identified which 4xx code is being thrown for each URL, you can go ahead and fix each URL based on the correct code.
Implementing redirects or removing URLs from your website and sitemap if a 404 code has been thrown.
Finding and fixing any errors in your code if a 400 error has been thrown (if the website is not down for scheduled maintenance).
Remove any paywall functionality so Googlebot can crawl any URLs that have been given a 403 error.
Blocked by ‘Page Removal Tool’
This is, perhaps, one of the easiest problems to solve. If you are seeing any URLs that have been blocked by the Page Removal Tool, it means that, at some point, the URL has been submitted to the Removals tool directly within Google Search Console for temporary removal:
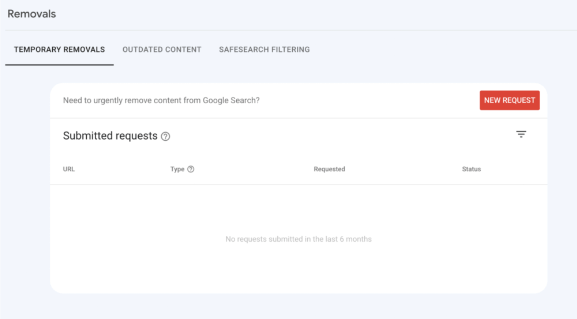
If any URLs are here that do not need to be, you can remove these from the Page Removal Tool and resubmit the URL to be crawled by Googlebot.
This tool is incredibly useful to remove pages from Google’s index for a short period. However, you have to manually add pages to this tool so if you are seeing the error, it means someone has submitted the URL to the tool at some point in time.
Crawled – Currently Not Indexed
Being presented with a crawled – currently not indexed error within Google Search Console is incredibly annoying because it means Googlebot has been able to crawl the URL without issue, but decided not to add it to its index for the time being, meaning any URLs given this error code are not showing up on Google’s SERPs.
This means the page, for whatever reason, is not seen as being quality enough to add to Google’s index. Luckily, there are a few things you can do to try and fix this.
You can add more internal links to the page. Links are Google’s “authority” marker, so adding more links (whether internal or external) to a page will ensure Google sees it as having more authority. External backlinks will (generally) be seen as more authoritative, but internal links still do a good job here too.
Check the content on the page. Is it thin? Low quality? You could manage to have the page added to Google’s index simply by adding more quality content to the page.
Does the content on the page match the search intent for the keywords you are trying to rank for? If not, change the content on the page to better match the intent of the searchers.
Discovered – Currently Not Indexed
If you are seeing the discovered – currently not indexed error within Google Search Console, it means that Google knows the URL exists but has not yet crawled or indexed the page yet.
This could be down to several reasons:
- Technical reasons.
- Lack of crawl budget.
- Excluded by design.
- Poor website structure.
- Google saving resources.
You have a few options to try and get this page crawled and indexed.
You can try submitting the URL manually to be crawled by Google. You can do this by searching the URL in the top bar of Google Search Console and clicking on the “Request Indexing” button:
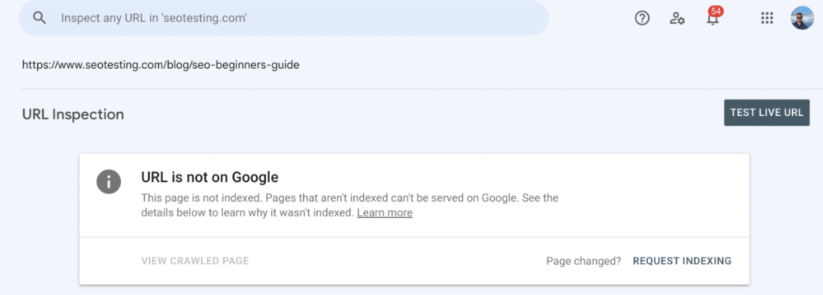
You should also check your server capacity to see if it can handle the number of times Googlebot is trying to crawl your website. You can check this in your server logs.
Is the page included in your sitemap? If not, and you want the page to be indexed, then you should add the URL to your sitemap.
Alternate page with proper canonical tag
The alternate page with proper canonical tag ‘error’ means Google has spotted a duplicate of the page, but it is correctly canonicalised. Technically this is not an error if indeed, you do not want this page to be indexed.
If you do want the page indexed, however, there is a little more work to do. You first need to remove the canonical tag and recrawl the URL with Google to see if this solves the issue. Sometimes this will work well and other times you are given another error such as duplicate without user-selected canonical which we will talk about next.
If you find that your URL is not being indexed even after removing the canonical tag, you need to change the content on the page so Google no longer sees this as a duplicate. You can do this by adding and/or removing certain content, adding videos, or better matching the page to the search intent.
Duplicate without user-selected canonical
If you are shown this error, it means Google has spotted duplicate pages on your website that have not been correctly canonicalised. This can happen a lot on large websites, especially large websites! So it is important to canonicalise all of your duplicate pages correctly.
First, establish which page you wish to be shown in Google’s index and ensure this points to itself with the canonical tag. This is referred to as a self-referencing canonical. We’ll talk about this a little more later.
Next, once you have established the page that needs to be indexed and added a self-referencing canonical tag, you need to find all the duplicate pages and point a canonical tag to the page you want to be indexed. You can identify these URLs within your Google Search Console report, but also through crawling your site with a tool like ScreamingFrog, OnCrawl or Sitebulb.
Once all of the pages have been given the correct canonical tags, ask Google to recrawl them using the manual tool we showed you a little earlier.
Duplicate, Google chose different canonical than user
If you are seeing this issue, it means Google has spotted duplicate content on your website that has not been marked with a canonical URL and has chosen to index the page it thinks is best for the job.
If the page that is being indexed is the correct page then you do not, technically, need to do anything here. However, it is best to add a self-referencing canonical to the page to avoid this error being shown in Google Search Console.
If the page that is being indexed is the wrong page, you need to canonicalise your URLs correctly. Self-reference canonical the correct URL, and point canonical tags on all your duplicate pages so Google understands which page is the correct page to index. Once this is done, resubmit all of your URLs for crawling by Google to save waiting.
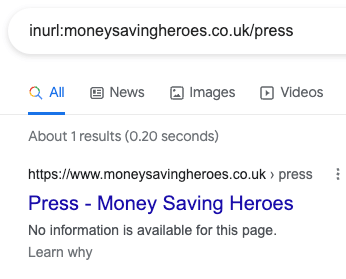
Indexed, though blocked by robots.txt
If you are seeing the indexed, though blocked by robots.txt error within Google Search Console, it means Google has indexed a page even though it has been blocked by your robots.txt file.
When this happens, the page will show in a SERP without a meta description. It shows without a meta description because Google wasn’t allowed to crawl the page to see the meta description.
There are a few different fixes for this, but you must first establish whether you want the page to be indexed.
If you do not want the page to be indexed, you could add a noindex tag to your page directly. But you will also need to allow Google to crawl the page so it can see the noindex tag. If there is another URL that targets the same keywords, you could add a canonical tag to that URL to this URL. You could also try removing all internal links to the page, password-protecting the page or deleting it and letting it 404.
If you want the page to be indexed, you need to establish why the page is not allowing crawling. There might be a block on the page directly, or a sitewide issue that you need to explore.
So there we have it, an introduction to all the error codes you could be given within Google Search Console and information on how to move past and fix each issue. If you are interested in making more of your Google Search Console data, give SEOTesting a try. We have a 14-day free trial that does not require a credit card.
Excluded by ‘Noindex’ tag
‘Excluded by noindex tag’ is a Google Search Console indexing status that appears when Googlebot crawls a page with a noindex meta tag. This means Google will not show this page in their search results or drop it as soon as possible to honour the no-index request. We’ve covered this error code, in detail, in this blog post.
Frequently Asked Questions
What are Google Search Console error codes?
Error codes in GSC show issues with crawling or indexing your pages. They help you understand why certain URLs are not appearing in Google Search.
What does a server error (5xx) mean in GSC?
A 5xx error means Googlebot could not access your page due to server issues. It can happen from internal errors, bad gateways, or server downtime.
How do I fix redirect errors in GSC?
Check your redirect chain. Remove loops, shorten chains, and fix broken or empty URLs. Ensure each URL points directly to the final destination.
What does ‘Crawled – Currently Not Indexed’ mean?
Google crawled your page but decided not to index it. Improve content quality, add internal links, or ensure it matches search intent.
What does ‘Discovered – Currently Not Indexed’ mean?
Google knows the page exists but has not crawled it yet. Submit the URL for indexing, add it to your sitemap, and check server capacity.
How do I fix a ‘URL blocked by robots.txt’ error?
Check your robots.txt file for disallow rules blocking the URL. Remove the block if you want the page indexed and re-upload the file.
What does ‘Duplicate, Google chose different canonical than user’ mean?
Google found duplicate pages and picked a different URL to index than your chosen canonical. Add correct self-referencing canonical tags and resubmit.
Testimonials
-

"Can totally recommend! It’s not only full of reports to easily identify low hanging fruit opportunities but also, the most straightforward platform to help run SEO tests"
Aleyda Solis, Intl SEO Consultant, Speaker & Author.
-

"SEOTesting has become one of my go-to SEO tools because it does so much with all the valuable data hidden in Google Search Console. It's the only thing that gives us the ability to use that data for keyword tracking, SEO tests, and quality testing."
Ruben Gamez, DocSketch