'Indexed, though blocked by robots.txt' shows up in Google Search Console when Google indexes a page blocked by a robots.txt file. It is slightly different to the "Excluded by 'Noindex' Tag" error you may also see in your Google Search Console page indexing report.
When this happens, your page will show up in the SERP without a meta description because Google wasn't allowed to crawl it.
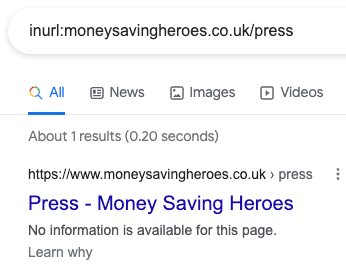
But don't be scared! This article will help you fix this issue.
You're about to learn what solutions to use to solve this Google Search Console error code, depending if you want the page to be indexed or removed.
How to find pages marked as 'Indexed, though blocked by robots.txt'?
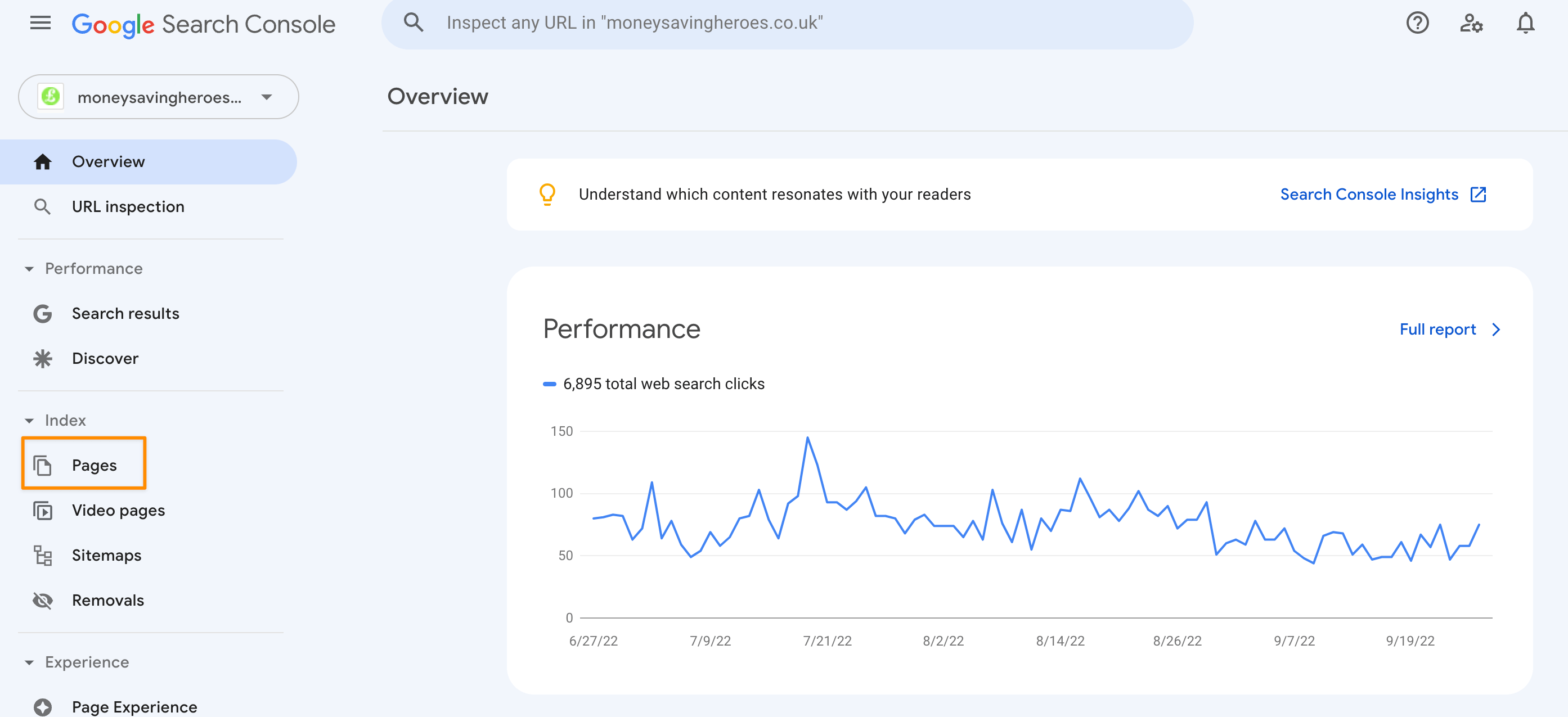
1. Head to the 'Pages' Report in Google Search Console
Open Google Search Console for the property you want to look at.
Then on the left sidebar, click on Pages (in the Index section).
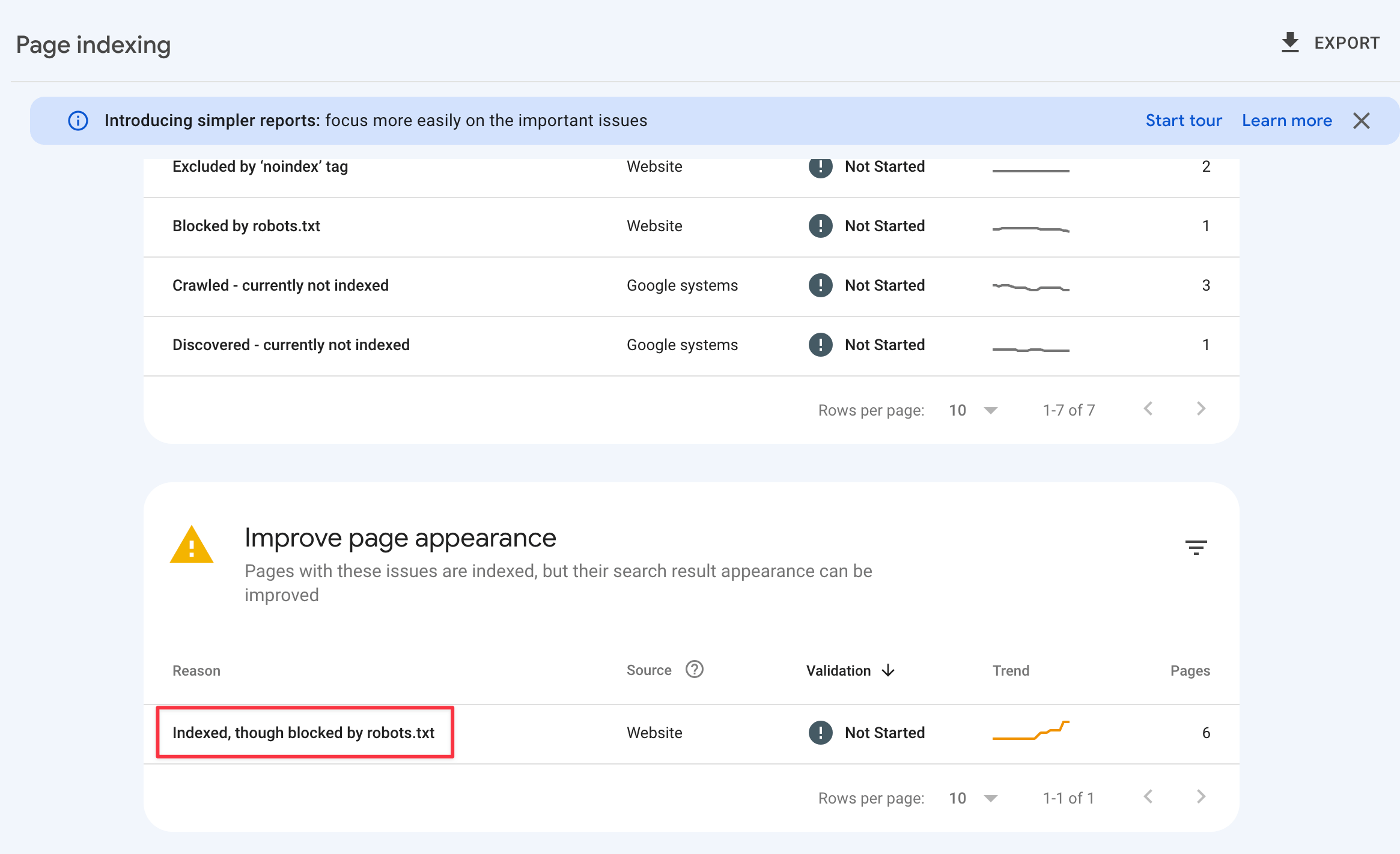
2. Find and click on 'Indexed, though blocked by robots.txt'
Scroll into the "Improve appearance" section and click on 'Indexed, though blocked by robots.txt'.
Now you should be looking at the list of URLs.
You can export this data if your site has lots of URLs or if you simply prefer to work on a spreadsheet.
How to fix 'Indexed, though blocked by robots.txt' when you don't want the page indexed
There are multiple reasons you might want to prevent a page from being indexed.
2 common examples are internal documents and pages not offering value to visitors.
This section will help you deal with those situations and everything in between.
Add a 'noindex' tag
The straightforward action when you do not want a page to be indexed is using a 'noindex' meta tag.
This tag makes Google drop the page from the search index, whether other pages link to it or not.
But first, you have to allow Googlebot to crawl the page in the robots.txt file. Otherwise, Google won't discover the 'noindex' tag.
You should also manually request the page to be crawled in GSC.
This happens because Google might not try to crawl the page themselves after being blocked by the robots file.
However, if you don't have permission to modify 'noindex' tags on your site, explore the other options below.
Implement a canonical URL
When more than one page approaches similar topics, you might decide to block crawling and prevent Google from indexing it. But when this option fails, it is time to use a canonical tag.
A canonical tag can help you more here than robots.txt to prevent keyword cannibalization if that's what you're worried about in the first place.
Remove internal links to the page
Google states that when other pages link to a page blocked by the robots exclusion file, they "could still index the URL without visiting the page".
This means that removing internal links pointing to the disallowed page might suffice for Google to drop it.
Password-protect the page
In the rare scenario that pages with private information get indexed by Google, a solution is password-protecting them.
You can use this approach to protect the information while Google doesn't drop the page.
This way, neither Google nor visitors can see the page's contents while it's indexed.
Delete the page
Deleting a page is a last resort solution, but this is the safest route when it shouldn't be indexed or accessible to anyone.
Removing the content from your site is the best way to ensure that not even Google can find it.
Just be sure that the page does not have any value to users on your website first, before deleting it from your site and Google's search results.
Sidenote: Follow Google's guidance on permanently removing a page from search results.
How to fix 'Indexed, though blocked by robots.txt' when you want the page indexed
A mistake may also prevent Google from crawling some pages you want to be indexed.
This section will focus on what you should do to make Googlebot crawl your site again.
Allow website crawling
The first thing to do is check the robots file and see if any directive is blocking crawling for the entire site.
If your robots.txt file looks like this, you've found the source of the problem:
User-agent: *
Disallow: /
This directive says that no user-agent (search engine crawler) is allowed to crawl the site.
When that's the case, delete those 2 lines to allow crawling again and manually request the page indexing on Google Search Console.
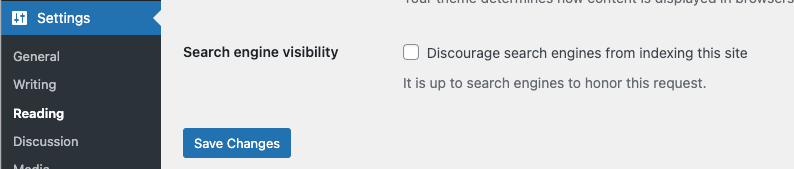
This robots.txt problem was quite common on WordPress sites prior to v5.3. A developer would check the "discourage search engines from indexing this site" box in the setting, but Google could still index pages without crawling them.
Unblock the user-agent
In this scenario, the robots.txt might block only some user-agents, such as Googlebot.
Again, look into your robots file and try to find a directive similar to this:
User-agent: Googlebot
Disallow: /
Removing that directive is usually enough to allow Google to crawl your site again.
In some edge cases, the directive could block only a site's section. An example of not allowing crawling the blog pages look like this:
User-agent: Googlebot
Disallow: /blog/
Testimonials
-

"Can totally recommend! It’s not only full of reports to easily identify low hanging fruit opportunities but also, the most straightforward platform to help run SEO tests"
Aleyda Solis, Intl SEO Consultant, Speaker & Author.
-

"SEOTesting.com has become one of my go-to SEO tools because it does so much with all the valuable data hidden in Google Search Console. It's the only thing that gives us the ability to use that data for keyword tracking, SEO tests, and quality testing."
Ruben Gamez, DocSketch