'Crawled - currently not indexed' is an excluded status for pages that Google has crawled but decided not to add to its search index. This means the URL will not appear in search results.
Google doesn't directly clarify why a page gets this status, but we know these pages often receive this status when Google considers it doesn't reach a quality threshold to get indexed.
In this article, we will focus on how to fix 'Crawled - currently not indexed' Google Search Console error code and improve the odds of a page showing up in the search results.
See 'Discovered - currently not indexed' if Google hasn't crawled the page you want to index.
This article makes up part of our Google Search Console tutorials and training section, make sure to check the others out.
What does this status mean?
The 'crawled - currently not indexed' status within your page indexing report in Google Search Console means that Google has actively crawled the page on your website, but chosen not to include it in its index.
This means that this page will not be showing up within Google's search engine results pages, for any query.
There could be a number of reasons for this, which we will discuss later on.
How to fix Crawled - currently not indexed
Below is a list of common issues causing pages to be 'Crawled - currently not indexed' and what possible solutions to make Google index them.
It's also worth pointing out that the Crawled - Currently Not Indexed error is slightly different to the "Excluded by 'Noindex' Tag" error which you may also see in your Google Search Console page indexing report. Whilst both have been crawled and not indexed, the Crawled - Currently Not Indexed error is more open to interpretation.
Improve internal linking
Google might decide that a page isn't worth indexing if your site has a poor internal link structure or the page doesn't have internal links. A page without any link pointing to it is called an orphan page.
To fix orphan pages or improve the internal linking structure, start by going to an existing page on your site, find a section of the article related to the topic page you want Google to index, and add a link.
You can internal linking opportunities by doing a site-based search in Google for the keyword the orphan page is targeting. The format of the query in Google would be:
Site:yourdomain.com 'orphan page target keyword'
The search results will be pages from your site that already use the target keyword and potentially provide internal linking opportunities.
Internal linking is essential, don't ignore it. This suggestion takes a couple of minutes and helps show the page is relevant.
Thin content/ Low-quality content
Pages with a low word count may lack information and be considered thin content by Google. If that's the case, they may crawl the page but exclude it from the search result page.
Thin content happens when your page has significantly fewer words than other top pages. For example, if all the search results have in-depth explanations with more than 3000 words, your page with 100s of words is likely considered thin content. However, if the top pages have mixed results with varying content lengths, your page with 100s of words may not have a thin content problem (as always it depends :)).
The solution generally for fixing thin content is to add more information to the page. Make the page long enough to cover the topic comprehensively without making it unnecessary long. Making a condensed and complete article that is valued by readers will be rewarded by Google with high rankings.
Google won't tell you a page has thin or low-quality content. Instead, you should check the search results and use your judgment.
Search Intent
Another cause for 'Crawled - currently not indexed' pages could be a mismatch in the search intent. This means there's a gap between your content and the content in the search results.
Here is an example of how search intent affects rankings for the query "how to calculate taxes". This query is informational, and there are mixed results, including tax calculators, videos, and "how-to" articles. So, when you target this query, you might succeed with different content types. However, when targeting the query "tax calculator", you are more likely to find success with a calculator tool than with a "how-to" article.
To guarantee you nail the search intent, check the pages ranking on the first page of Google before creating your content.
The solution to fix Crawled - currently not indexed because of a mismatch in search intent is to rewrite or change the content on the page.
Page with near-duplicate content
As we have seen in our 'Discovered - currently not indexed' guide, Google wants to be efficient with its resources and crawl budget. One thing Google doesn't like is duplicated content.
John Mueller said there are no penalties for duplicated content, but that doesn't mean Google will index it. In fact, they don't want to index duplicate content. But what will Google do if they think one of the pages on your site is duplicated? Most likely, the page will be labeled 'Crawled - currently not indexed'.
Situations where duplicated content might happen:
- eCommerce websites with lots of variations for the same product with short product descriptions;
- websites with a lot of user-generated content;
- pages approaching the same or similar topic on a website.
Google wants to avoid indexing duplicated pages from the same website to improve user experience. This makes Google filter out some results.
I recommend you check the Performance report to see what pages are already ranking for a target query, that your page is going after.
When pages approach similar topics, consider adding a canonical tag to tell Google it's okay to index only one of them. With this tag, you tell Google which page is the most relevant and which you want to index. Usually, they respect canonical tags.
However, if you consider the pages aren't similar or you don't want to use a canonical tag, consider changing the content from one of the pages.
Structured data mismatch
Structured data helps search engines understand the content of a page. You can check the status of your structured data on your Google Search Console Enhancements tab.
Keeping track of your structured data is paramount, as errors within your structured data can cause Google to, occasionally, refuse to index your page even after it has been crawled. Examples of this include product pages which we will talk about in our next section.
Errors in structured data can cause Google to misinterpret the page, which might not only mean your page not showing up in rich snippets, but not appearing in Google's index altogether. Warnings, however, are slightly different as they may still allow your page to be indexed, they just might not show in rich snippets.
Expired products
One common problem I see a lot on ecommerce websites when going through lists of pages with the crawled - currently not indexed error is product pages (sometimes referred to as PDPs or Product Display Pages) which show products as out of stock or not available.
When crawling URLs, it appears Googlebot checks to see if the product is available, and if not, will list it as crawled - currently not indexed. This makes a lot of sense for Google to do as they focus heavily on user experience and would not want URLs showing up on Google if the products are not available.
If you run an ecommerce website and you are experiencing the crawled - currently not indexed error on your product pages, check your stock feed to ensure all products which are available are showing this on the page itself. You can then manually ask Google to re-crawl your URLs.
Google's John Mueller has some good information on dealing with out of stock products.
301 redirects
Whilst this is a rare issue, especially on larger more authoritative websites where URLs get crawled quickly and regularly, it can still occur.
Occasionally we see the destination URLs of redirected pages showing up in the crawled - currently not indexed report. This is not down to redirects being improperly redirected, but more down to the rate in which Google crawl your website. We can, sometimes, see that Google is crawling the destination URL but not including it in the index. This can be identified by looking at the SERP.
One common way to fix this is to implement a temporary sitemap.xml file. Take all the URLs from the crawled - not currently index report, match them up in Excel or Google Sheets with redirects that have been set-up, create a sitemap (you can do this using ScreamingFrog) and upload it to your Google Search Console dashboard.
Private content
Occasionally, Googlebot can access content that it should not be able to access. These are the instances where you will see crawled - currently not indexed appearing as an error on these private URLs.
Examples of private pages could be development environments, pages which should only be able to be accessed post-login, paywalled content and more.
This can happen if Google's crawling of your website is not focussed. Googlebot will go anywhere and everwhere it can in an effort to find valuable content for users.
Run a crawl of your website using ScreamingFrog, Sitebulb or a similar tool and get a list together of pages which should not be crawled. You can then decide what the best course of action is to take. This might be removing all internal links to these pages, and removing it from the sitemap, so Googlebot simply cannot find the page. Or it could mean some work on your robots.txt file to stop Googlebot crawling these parts of your website entirely.
Other factors
False positive
A false positive is when Google Search Console reports a page as excluded, but the URL inspection tool or testing the live URL shows your page is indexed. This scenario is considered a false positive in the Google Search Console coverage.
To do a live URL test:
- Go to Google.com and put your page URL as the query. For example, domain.com/your-blog-post;
- Then look at the results and look for your page URL;
If your page appears in the search results it means it is indexed, even if in Google Search Console it says the page is excluded. This is what is called a false positive.
There's nothing you need to do in this scenario, as this is only a reporting error from the Search Console.
Paginated URLs
Blogs and eCommerce stores might use pagination to separate content and make it manageable to navigate. Paginated URLs are pages with a number at the end representing the page - for example, www.myDomain.com/blog/page/2.
Google may decide not to index these pages. Whether you decide to attempt to fix this issue with paginated URLs, will depend on whether you see value from them being in the search results. Will the paginated URL actually rank for anything?
Check out Google's best practices for pagination or this guide about pagination for SEO.
RSS feed URL
RSS feeds are helpful for content distribution, but these URLs aren't meant to be read by humans as they don't have formatting.
If Google crawls but doesn't index your RSS feeds, there's nothing wrong with it, and you shouldn't worry.
Crawled - Currently not Indexed vs Discovered - Currently not Indexed
Whilst these two statuses sound incredibly similar, there is one big difference. Discovered - currently not indexed means that Googlebot has found the URL but decided not to crawl it. This could be down to your robots.txt file or other factors, which we discuss here. Crawled - currently not indexed means that Googlebot has actively crawled the page but decided not to add it to its index for one of the reasons explained above.
FAQs
Is 'Crawled - currently not indexed' an error?
No. Crawled - currently not indexed is an excluded status from the search results. Whether you need to take any action on the page will depend on the results of your investigation of the page based on internal linking, content quality, and the other issues discussed above.
Where do I find Crawled - currently not indexed?
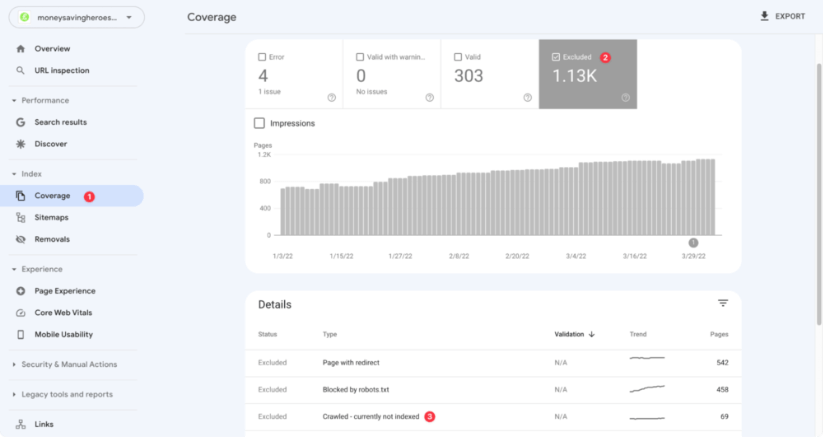
You can find pages with the status 'Crawled - currently not indexed' on the Coverage report on the Excluded tab.
Why are my pages not being indexed by Google?
There are many reasons why Google might not index your pages.
You can do the following to get it indexed by Google:
- Use the URL inspection tool on Google Search Console to see if indexing the page is possible.
- Follow the steps mentioned above in this guide.
Can pages with redirects be marked as 'Crawled - currently not indexed'?
No. Google Search Console has a separate excluded status for pages with redirects, so they aren't mixed with 'Crawled - currently not indexed'.
Also, Google Search Advocate, John Mueller replied on Twitter that Google doesn't index pages with redirects.
Testimonials
-

"Can totally recommend! It’s not only full of reports to easily identify low hanging fruit opportunities but also, the most straightforward platform to help run SEO tests"
Aleyda Solis, Intl SEO Consultant, Speaker & Author.
-

"SEOTesting.com has become one of my go-to SEO tools because it does so much with all the valuable data hidden in Google Search Console. It's the only thing that gives us the ability to use that data for keyword tracking, SEO tests, and quality testing."
Ruben Gamez, DocSketch